
[DataCon 2022] 大数据安全分析竞赛 物联网赛道writeup
无经验新手队伍的writeup,轻喷
一、固件基地址识别
1.1 题目要求

1.2 思路
- 一般对于一个完整的 RTOS 设备固件而言,通常可以通过解压固件包并在某个偏移上搜索到内核加载基址的信息,参考:[RTOS] 基于VxWorks的TP-Link路由器固件的通用解压与修复思路 。但是赛题1给的是若干个不同厂商工具链编译的 RTOS 内核 Image,无法直接搜索到基址信息;
内核 Image 中虽然没有基址信息,但是有很多的绝对地址指针(pointer)和 ASCII 字符串(string),而字符串相对于 Image Base 的偏移量是固定的,所以只有选取正确的基址值时,指针减去基址才能得到正确的 ASCII 字符串偏移;
- 即需要满足如下关系:
pointer_value - image_base = string_offset
- 即需要满足如下关系:
所以实现方式大致为:
- 检索所有的字符串信息,并搜集
string_offset - 按照目标架构的
size_t长度搜集所有的pointer_value - 按照一定步长遍历
image_base,计算所有image_base取值下string_offset的正确数量,并统计出正确数量最多的前几个候选image_base输出
- 检索所有的字符串信息,并搜集
- 在此基础上可以增加一些优化措施,比如可以像 rbasefind2 一样通过比较子字符串差异以获得
image_base候选值,这样就不需要从头遍历所有的image_base,速度更快
1.3 实现
1.3.1 相关工具
基于 soyersoyer/basefind2 和 sgayou/rbasefind 项目以及 ReFirmLabs/binwalk 工具实现
rbasefind主要提供了3个控制参数:搜索步长,最小有效字符串长度以及端序binwalk用于通过指令比较的方式检查 Image 文件的架构和端序- 通过多次调整步长和字符串长度参数进行
rbasefind,可以得到可信度最高的 Image Base 值,将其作为答案提交
1.3.2 脚本
import os
import sys
import subprocess
chall_1_data_path = "../dataset/1"
file_list = os.listdir(chall_1_data_path)
vxworks = {15, 21, 36, 37, 44, 45, 49}
ecos = {4, 2, 30, 49, 18, 45, 33, 5, 20, 32, 43}
answer = {}
def get_default_answer(data_i):
if int(data_i) in vxworks:
return hex(0x40205000)
elif int(data_i) in ecos:
return hex(0x80040000)
else:
return hex(0x80000000)
def check_endian(path):
out, err = subprocess.Popen(
f"binwalk -Y \'{path}\'", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE).communicate()
# print(out)
if b", little endian, " in out:
return "little"
elif b", big endian, " in out:
return "big"
else:
return "unknown"
if __name__ == "__main__":
#file_list = ["2", "5"]
cnt = 0
for file in file_list:
cnt += 1
print(f"[{cnt}/{len(file_list)}] Processing file: {file}...")
file_path = os.path.join(chall_1_data_path, file)
endian = check_endian(file_path)
if endian == "little":
cmd = f"./rbase_find -o 0x100 -m 10 \'{file_path}\' 2>/dev/null | sed -n \"1p\""
elif endian == "big":
cmd = f"./rbase_find -o 0x100 -m 10 -b \'{file_path}\' 2>/dev/null | sed -n \"1p\""
elif endian == "unknown":
cmd = f"./rbase_find -o 0x100 -m 10 \'{file_path}\' 2>/dev/null | sed -n \"1p\""
try:
out, err = subprocess.Popen(
cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE).communicate()
except Exception as e:
# error
print(f"Rbase file \'{file_path}\' failed with:", e)
answer[file] = get_default_answer(file)
continue
out = out.decode().strip()
print(f"File {file_path} done with:", out)
colsep = out.split(":")
if len(colsep) != 2:
answer[file] = get_default_answer(file)
continue
# success
base_address = colsep[0].strip()
base_address = hex(int(base_address, 16))
print(f"Add '{file}:{base_address}\' => answer")
answer[file] = base_address
# sort answer
answer = dict(sorted(answer.items(), key=lambda item: int(item[0])))
with open("rbase_answer.txt", "w") as f:
for key, value in answer.items():
f.write(f"{key}:{value}\n")二、函数符号恢复
2.1 题目要求
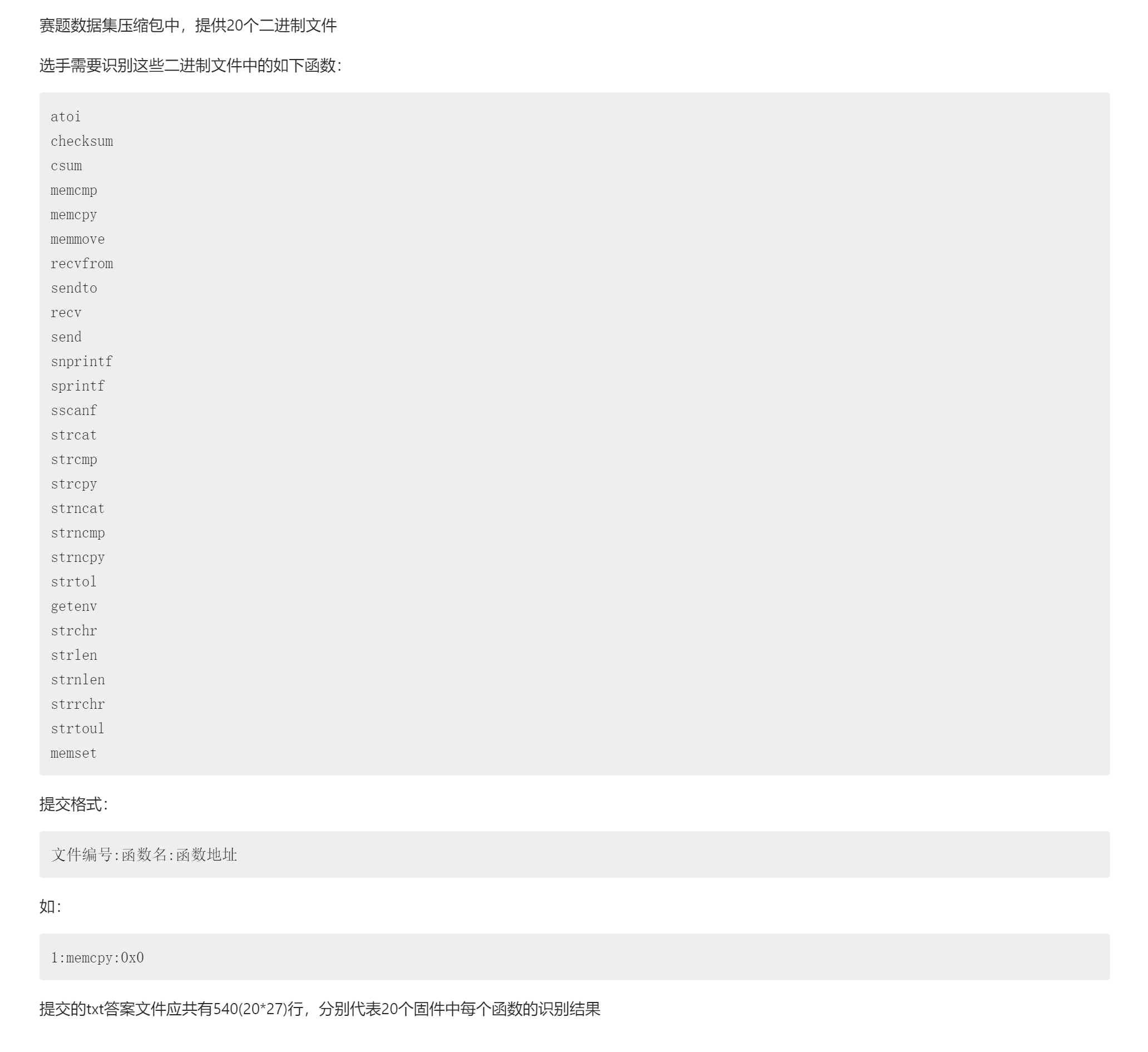
2.2 思路
从题目要求来看应该是比较经典的二进制匹配问题了,相关工具和公开的思路都不少。最开始看到题目我们就有了如下两种思路。
2.2.1 Binary Match
第一种是传统的 静态二进制匹配 方式,提取目标函数的 CFG 特征或者 sig 等信息,将其与无符号二进制中的函数进行比较,并输出匹配结果的可信度。由于尝试了几个现成的工具后发现效果不尽人意,暂时也没想到优化措施,就暂时搁置了这个思路。
后续和 C0ss4ck 师傅交流了一下,他是通过魔改的 Gencoding 以及大量提取各种各样 Glibc 中的函数特征而实现的二进制匹配。一开始效和我分数差不多,但是后来他针对性的提取了很多特殊 RTOS 工具链构建出来的 kernel 的函数特征,效果突飞猛进,相关特征库也已经开源:Cossack9989/BinFeatureDB: Binary Feature(ACFG) Database for DataCon2022-IoT-Challenge-2 (github.com)。
2.2.2 Emulated Match
第二种是通过 动态模拟执行 来匹配函数。这个思路是比赛时想到的,之前没有见过相关工具,也没有阅读过相关资料,直觉上觉得效果会不错,而且很有挑战性,于是着手尝试实现这个思路。
2.2.2.1 概要
前期准备:
- 测试用例:为要匹配的所有函数设计输入和输出用例
- 函数行为:为一些该函数特有的访存行为定义回调函数,如
memcpy和memcpy会对两个指针参数指向的地址进行访存 - 系统调用:监控某些函数会使用的系统调用,如
recv,recvmsg,send,sendto等socket函数依赖于某些底层调用
- 提取出函数的起始地址,为该函数建立上下文(context),拍摄快照(snapshot)并保存,添加回调函数,进入预执行状态
- 在预执行状态下完成参数传递等工作
- 开始模拟执行,执行结束后会触发返回点上的回调,进入检查逻辑。通过检查测试用例、函数行为以及系统调用等特征是否符合预期,返回匹配结果
- 恢复快照(restore),继续匹配下一个目标函数,循环往复
- 输出某个起始地址上所成功匹配的所有目标函数(不一定唯一)
2.3 实现
2.3.1 基本架构

图画得稍微有点不清楚的地方,Snapshot 在一个 Test Case 中只执行一次,往后只完成 Args Passing 就行,懒得改了...
这是我们实现的基于模拟执行的函数符号恢复工具的基本架构,由 BinaryMatch 和 Solver 两部分组成:
- BinaryMatch 负责遍历加载目标文件,构建出可的模拟执行对象,并请求 Solver 匹配目标函数
- Solver 则是使用模拟执行的方式,将运行结果和预期结果作比较,判断是否匹配。而与一般匹配方式不同的是,不需要提前编译并搜集函数特征库,但是需要手动实现某个函数的 matcher
2.3.2 BinaryMatch 类
首先将待匹配的无符号 ELF 文件导入 IDA 或者 Radare2 等反编译软件,导出函数列表(其中包含函数的入口地址)和基址信息
- 由于题目强调了基址不同时以 IDA 为准,这里绕了点弯使用 IDA 导出的结果
ida_res_file = os.path.join(ida_res_dir, f"{file_r_n}_ida_res.txt")
with open(ida_res_file, "r") as f:
ida_res = json.loads(f.read())
bin = BinaryMatch(
file_path, func_list=ida_res["func_list"], base=ida_res["image_base"])
res[file_path] = bin.match_all()将函数列表和 ELF 文件作为参数构造一个 BinaryMatch 对象,该对象负责组织针对当前 ELF 的匹配工作:
识别 ELF 架构和端序,选用指定参数去创建一个 Qiling 虚拟机对象,用于后续模拟执行
_archtype = self._get_ql_arch() _endian = self._get_ql_endian() if _archtype == None or _endian == None: self.log_warnning(f"Unsupported arch {self.arch}-{self.bit}-{self.endian}") return False ... ql = Qiling( [self.file_path], rootfs="./fake_root", archtype=_archtype, endian=_endian, ostype=QL_OS.LINUX, #multithread=True verbose=QL_VERBOSE.DISABLED #verbose=QL_VERBOSE.DEBUG ) entry_point = ql.loader.images[0].base + _start - self.base exit_point = ql.loader.images[0].base + _end - self.base由于某些 ELF 编译所用的工具链比较特殊导致 Qiling 无法自动加载,需要单独处理,是一个瓶颈
遍历 BinaryMatch 类中默认的或用户指定的匹配目标(Target),使用注册到 BinaryMatch 类上的对应架构的 Solver 创建一个 solver 实例,调用其中的 solve 方法发起匹配请求:
如:一个 x86_64 小端序的 ELF 会请求到
Amd64LittleSolver.solve()... "amd64": { "64": { "little": Amd64LittleSolver } } ...每次请求可以看成传递了一个3元组:
(虚拟机对象, 欲匹配函数名, 待匹配函数入口)solver = self._get_solver() res = solver.solve(ql, target, entry_point, exit_point) # solveexit_point 暂时没有作用,可忽略
- 返回匹配结果
2.3.3 Solver 类
Solver.solve()方法def solve(self, ql: Qiling, target: str, _start: int, _end: int): self._build_context(ql) matcher = self._matchers.get(target, None) if matcher == None: self.log_warnning(f"No mather for \"{target}()\"") return False _test_cases = self._get_test_cases(target) if _test_cases == None: self.log_warnning(f"No test cases for {target}!") return False _case_i = 0 # Snapshot: save states of emulator ql_all = ql.save(reg=True, cpu_context=True, mem=True, loader=True, os=True, fd=True) ql.log.info("Snapshot...") for case in _test_cases: _case_i += 1 # global hooks self._set_global_hook(ql, target, _start, _end) # match target funtion if not matcher(ql, _start, _end, case): self.log_warnning(f"Test Case {_case_i}/{len(_test_cases)} failed!") return False # Resume: recover states of emulator ql.clear_hooks() # note that it can not unmap the mapped memory. Fuck you Qiling! It is a shit bug! ql.restore(ql_all) ql.log.info("Restore...") self.log_success(f"Test Case {_case_i}/{len(_test_cases)} passed!") return True调用
Solver.solve()方法后,开始构建函数运行所需的上下,文这些上下文信息包括:def _build_context(self, ql: Qiling): # Due to Qiling's imperfect implementation of Hook, it's like a piece of shit here mmap_start = self._default_mmap_start mmap_size = self._default_mmap_size # Prevent syscall read def null_read_impl(ql: Qiling, abi: int, length: int, flags: int, sig: int): self.log_warnning("Ingnore syscall READ!") return 0 ql.os.set_syscall('read', null_read_impl, QL_INTERCEPT.CALL) # Prevent syscall setrlimit def null_setrlimit_impl(ql: Qiling, abi: int, length: int, flags: int, sig: int): self.log_warnning("Ingnore syscall SETRLIMIT!") return 0 ql.os.set_syscall('setrlimit', null_setrlimit_impl, QL_INTERCEPT.CALL) # args buffer ql.mem.map(mmap_start, mmap_size, UC_PROT_ALL) # return point ql.mem.map(self._default_return_point, 0x1000, UC_PROT_ALL)- 参数内存:为即将可能要使用的指针类型的参数(如:
char *buf)创建对应的缓冲区ql.mem.map(mmap_start, mmap_size, UC_PROT_ALL); - 返回点:通过 map 方法开辟一段 RWX 内存,将其作为返回地址写入到返回地址寄存器或将返回地址压入栈中,后续只要统一在这个地址上注册 Hook 就可以在函数退出时自动触发;
- 系统调用:屏蔽一些可能会发生异常或者导致执行流阻塞的系统调用。如: setrlimit 可能会导致进程资源受限而被系统 kill 掉,以及对 STDIN 的 read 调用可能会阻塞当前线程;
- 其它:特定于某些架构上的问题可以通过重写
_build_context方法进行补充完善。如:x86_64 下需要直接调用底层 Unicorn 接口给UC_X86_REG_FS_BASE寄存器赋值,防止访问 TLS 结构体时出现异常;
- 参数内存:为即将可能要使用的指针类型的参数(如:
- 上下文构造完毕后,进入 预执行 状态,在这个状态下调用快照功能将 Qiling Machine 的状态保存下来。因为一个目标函数的测试用例可能有好几个,使用快照可以防止用例间产生干扰,并且避免了重复构建上下文信息
调用
_set_global_hook设置全局 hook,主要是便于不同架构下单独进行 debug 调试def _set_global_hook(self, ql: Qiling, target: str, _start: int, _end: int): def _code_hook(ql: Qiling, address: int, size: int, md: Cs): _insn = next(md.disasm(ql.mem.read(address,size), address, count=1)) _mnemonic = _insn.mnemonic _op_str = _insn.op_str _ins_str = f"{_mnemonic} {_op_str}" self.log_warnning(f"Hook <{hex(address)}: {_ins_str}> instruction.") ql.hook_code(_code_hook, user_data=ql.arch.disassembler) return借助 _set_global_hook 实现简单的调试功能,检查执行出错的指令
检查类的内部是否实现了名为
_match_xxxx的私有方法,其中xxxx是待匹配目标函数的名称,如strlen对应_match_strlen。如果有实现该方法则取出作为 matcher 传入 Qiling Machine,函数地址,测试用例,并等待返回匹配结果matcher = self._matchers.get(target, None) ... if not matcher(ql, _start, _end, case): self.log_warnning(f"Test Case {_case_i}/{len(_test_cases)} failed!") return False以
_match_strlen为例,一个 matcher 的实现逻辑大致如下:def _match_strlen(self, ql: Qiling, entry_point: int, exit_point: int, case): match_result = False # 需要注册一个_return_hook到返回点上 def _return_hook(ql: Qiling) -> None: nonlocal match_result nonlocal case # check output assert self._type_is_int(case["out"][0]) if case["out"][0].data == self._get_retval(ql)[0]: match_result = True ql.stop() ql.hook_address(_return_hook, self._default_return_point) self._pass_args(ql, case["in"]) self._run_emu(ql, entry_point, exit_point) return match_result有一些函数涉及到缓冲区访问,或者会将结果保存到缓冲区中,实现上则更麻烦,如
_match_memcmp:def _match_memcmp(self, ql: Qiling, entry_point: int, exit_point: int, case): match_result = False _dest_mem_read = False _dest_mem_addr = self._get_arg_buffer_ptr(0) _src_mem_read = False _src_mem_addr = self._get_arg_buffer_ptr(1) _mem_size = self._default_buffer_size _cmp_len = case["in"][2].data # memcmp() function must read this two mem def _mem_read_hook(ql: Qiling, access: int, address: int, size: int, value: int): nonlocal _dest_mem_read, _src_mem_read nonlocal _dest_mem_addr, _src_mem_addr nonlocal _mem_size if access == UC_MEM_READ: if address >= _dest_mem_addr and address < _dest_mem_addr + _mem_size: _dest_mem_read = True if address >= _src_mem_addr and address < _src_mem_addr + _mem_size: _src_mem_read = True return _hook_start = self._default_mmap_start _hook_end =_hook_start + self._default_mmap_size ql.hook_mem_read(_mem_read_hook, begin=self._default_mmap_start, end=_hook_end) def _return_hook(ql: Qiling) -> None: nonlocal match_result nonlocal case _dst_buffer = case["in"][0].data _src_buffer = case["in"][1].data # Check whether the buffer is accessed if _dest_mem_read and _src_mem_read: # check memory consistency if case["in"][0].data == self._get_arg_buffer(ql, 0, len(case["in"][0].data)) and\ case["in"][1].data == self._get_arg_buffer(ql, 1, len(case["in"][1].data)): # check memcmp result if _dst_buffer[:_cmp_len] == _src_buffer[:_cmp_len]: if self._get_retval(ql)[0] == 0: match_result = True else: match_result = False else: if self._get_retval(ql)[0] != 0: match_result = True else: match_result = False ql.stop() ql.hook_address(_return_hook, self._default_return_point) self._pass_args(ql, case["in"]) self._run_emu(ql, entry_point, exit_point) return match_result在 matcher 中会调用
_pass_args方法,按照预先设置好的参数寄存器和传参约定,进行测试用例的参数传递def _pass_args(self, ql: Qiling, input: list[EmuData]): mmap_start = self._default_mmap_start max_buffer_args = self._default_max_buffer_args buffer_size = self._default_buffer_size buffer_args_count = 0 _arg_i = 0 for _arg in input: if _arg_i >= len(self._arg_regs): ValueError( f"Too many args: {len(input)} (max {len(self._arg_regs)})!") if self._type_is_int(_arg): ql.arch.regs.write(self._arg_regs[_arg_i], _arg.data) elif _arg.type == DATA_TYPE.STRING: if buffer_args_count == max_buffer_args: ValueError( f"Too many buffer args: {buffer_args_count} (max {max_buffer_args})!") _ptr = mmap_start+buffer_args_count*buffer_size ql.mem.write(_ptr, _arg.data+b"\x00") # "\x00" in the end ql.arch.regs.write(self._arg_regs[_arg_i], _ptr) buffer_args_count += 1 elif _arg.type == DATA_TYPE.BUFFER: if buffer_args_count == self._default_max_buffer_args: ValueError( f"Too many buffer args: {buffer_args_count} (max {self._default_max_buffer_args})!") _ptr = mmap_start+buffer_args_count*buffer_size ql.mem.write(_ptr, _arg.data) ql.arch.regs.write(self._arg_regs[_arg_i], _ptr) buffer_aargs_count += 1 _arg_i += 1目前简单将参数分为了:整数、字符串以及其它缓冲区(包括复杂结构体),未来可以继续扩展
- 调用
_run_emu开始运行 Qiling Machine,运行时会不断触发设置好的Hook,此处略过。由于事先将返回地址设置到了一块空内存上,并在这块内存设置了 Return Hook,所以最终停止执行只会有三个原因:执行超时,内存错误,触发 Return Hook - 运行前注册的
_return_hook其实主要就是起到检查作用,检查测试用例的输入传入未知函数后得到的结果是否符合预期。很多时候函数的返回值并不能说明函数的执行效果。比如memmove函数需要检查 dest 缓冲区是否拷贝了正确的字节;再比如snprintf需要模拟格式化字符串输出结果后,再与缓冲区中的字符串作比较。
在 matcher 退出后,需要清空本次测试用例挂上的 Hook,并恢复快照,准备比较下一个测试用例
for case in _test_cases: ... ql.clear_hooks() ql.restore(ql_all) ql.log.info("Restore...") self.log_success(f"Test Case {_case_i}/{len(_test_cases)} passed!")
2.3.4 减少 False Positive 思路
- 近似函数错配:如果将函数视为 $F(x)$,基于模拟执行的函数匹配思路就是将 $y = F(x)$ 中的 $(x, y)$ 对与已知用例进行拟合,其得到的输入输出终究不能完全揭示未知函数的内部结构(如CFG)。所以容易出现在一个未知函数上成功匹配了错误的目标函数,最典型的例子就是在 strcpy 上匹配了 strncpy,在 memcmp 上匹配了 strcmp,于是需要巧妙设计测试用例
- 特征不明显函数错配:并且类似 memcmp 这一类只返回 true or false 的函数,模拟执行结果很可能和所设计的测试用例恰好匹配,于是需要引入一些 “超参数” 增加判断依据
2.3.4.1 巧妙设计测试用例
给 strcmp 和 memcmp 设置带
\x00截断的测试用例:"memcmp": [ { "in": [ EmuData(b"A"*0x20, DATA_TYPE.BUFFER), EmuData(b"A"*0x20, DATA_TYPE.BUFFER), EmuData(0x20, DATA_TYPE.INT32) ], "out": [ EmuData(0, DATA_TYPE.INT32) ] }, { "in": [ EmuData(b"AAAAaaaa", DATA_TYPE.BUFFER), EmuData(b"AAAAAAAA", DATA_TYPE.BUFFER), EmuData(0x8, DATA_TYPE.INT32) ], "out": [ EmuData(-1, DATA_TYPE.INT32) ] }, { "in": [ EmuData(b"aisudhakaisudhak", DATA_TYPE.BUFFER), EmuData(b"AAAAAAAAaisudhak", DATA_TYPE.BUFFER), EmuData(0x10, DATA_TYPE.INT32) ], "out": [ EmuData(-1, DATA_TYPE.INT32) ] }, { "in": [ EmuData(b"AAAAAAAA\x00AAAAAAA", DATA_TYPE.BUFFER), EmuData(b"AAAAAAAA\x00BBBBBBB", DATA_TYPE.BUFFER), EmuData(0x10, DATA_TYPE.INT32) ], "out": [ EmuData(-1, DATA_TYPE.INT32) ] }, ], "strcmp": [ { "in": [ EmuData(b"A"*0x20, DATA_TYPE.STRING), EmuData(b"A"*0x20, DATA_TYPE.STRING), ], "out": [ EmuData(0, DATA_TYPE.INT32) ] }, { "in": [ EmuData(b"AAAAaaaa", DATA_TYPE.STRING), EmuData(b"AAAAAAAA", DATA_TYPE.STRING), ], "out": [ EmuData(-1, DATA_TYPE.INT32) ] }, { "in": [ EmuData(b"AAAAAAAA\x00AAAAAAA", DATA_TYPE.STRING), EmuData(b"AAAAAAAA\x00BBBBBBB", DATA_TYPE.STRING), ], "out": [ EmuData(0, DATA_TYPE.INT32) ] }, ],给 atoi 和 strtol 设计带有 base 参数的测试用例,并且在匹配 atoi 前将 base 参数(atoi 本身没有这个参数)对应的寄存器写 0
"atoi": [ { "in": [ EmuData(b"12345", DATA_TYPE.STRING) ], "out": [ EmuData(12345, DATA_TYPE.INT32) ] }, { "in": [ EmuData(b"1923689", DATA_TYPE.STRING) ], "out": [ EmuData(1923689, DATA_TYPE.INT32) ] }, ], "strtoul": [ { "in": [ EmuData(b"12345", DATA_TYPE.STRING), EmuData(0, DATA_TYPE.INT32), # endptr EmuData(10, DATA_TYPE.INT32) # base ], "out": [ EmuData(12345, DATA_TYPE.INT32) ] }, { "in": [ EmuData(b"12345", DATA_TYPE.STRING), EmuData(0, DATA_TYPE.INT32), # endptr EmuData(16, DATA_TYPE.INT32) # base ], "out": [ EmuData(74565, DATA_TYPE.INT32) ] }, { "in": [ EmuData(b"0x100", DATA_TYPE.STRING), EmuData(0, DATA_TYPE.INT32), # endptr EmuData(16, DATA_TYPE.INT32) # base ], "out": [ EmuData(256, DATA_TYPE.INT32) ] }, ]... # Easy to distinguish from strtoul/strtol ql.arch.regs.write(self._arg_regs[1], 0xdeadbeef) ql.arch.regs.write(self._arg_regs[2], 0xffff) ...
2.3.4.2 增加额外的检查
如之前所述,只使用 memcmp 类函数的返回值匹配时误报率较大。解决的思路是增加两个检查:
- 添加 dest 和 src 缓冲区的内存访问 Hook,保证运行时这两个参数都要被访问到
- 运行结束后检查 dest 和 src 缓冲区中的值是否不变,memcmp 函数不应该改变这两个缓冲区的值
- 经过实际测试,增加额外检查后,近似函数导致的误报率大大降低
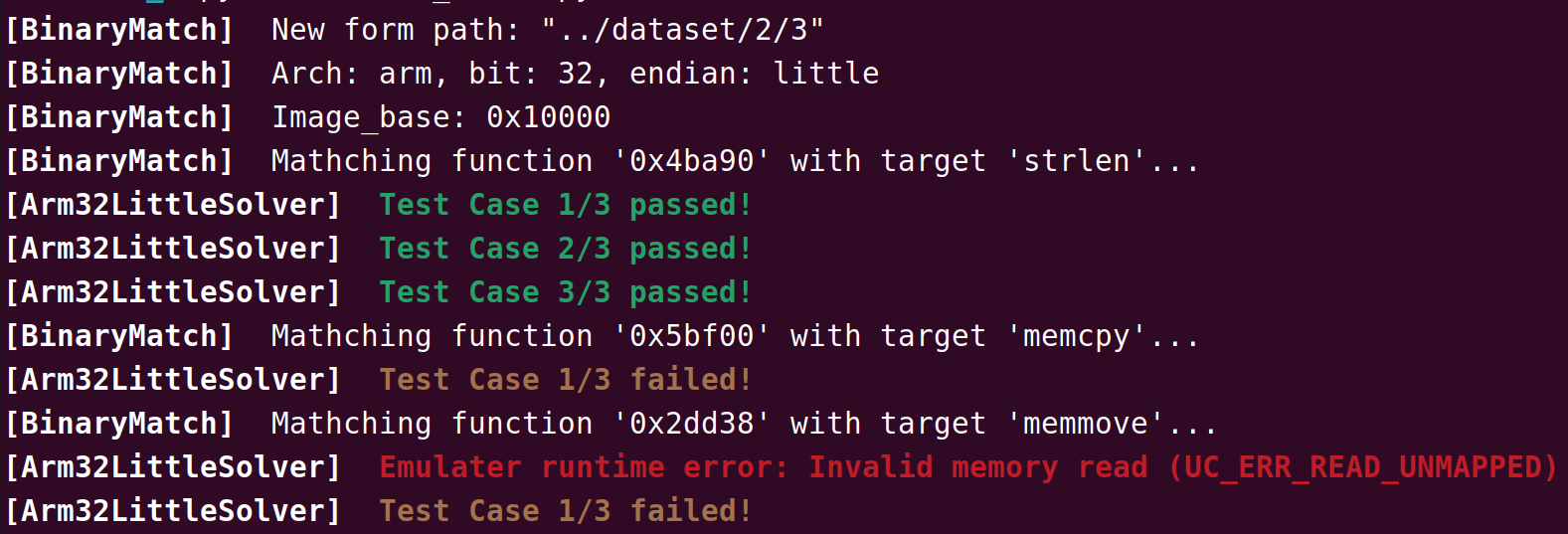
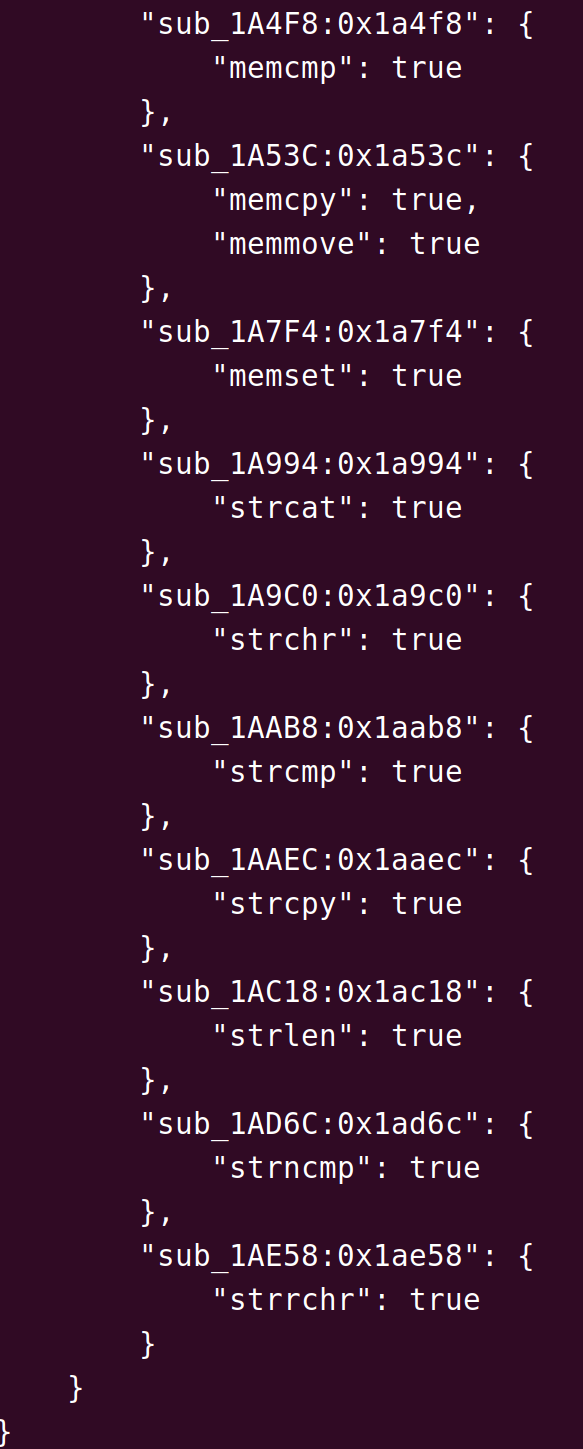
2.3.5 运行效果
2.4 不足与改进
- [指令] 第一个也是最严重的一个不足,直接导致了分数不是很理想。Qiling 模拟执行框架不支持带有 thumb 的 ARM ELF,模拟执行不起来,这直接导致了本次测试集中很多 ARM32 的测试用例无法使用,非常影响分数。如果要解决这一点,目前来说要么等 Qiling 支持 thumb,要么直接换用 QEMU 作为模拟执行的后端。但是 QEMU 的缺点在于构造上下文很麻烦,添加回调不方便,监视和修改内存困难。所以我们在有限时间内还没有更好的解决方案;
- [模拟] 某些厂商 RTOS 工具链编译出来的 ELF 文件结构比较奇怪,暂时不知道因为什么原因导致 Qiling 无法直接加载并提示
load_elf_segments错误。虽然说可以通过手动 map ELF文件到指定的 Base 上,但是这总归是个极大影响使用体验的东西; - [上下文] 模拟执行前的上下文构建无法兼顾到一些只有在程序运行时才设置好的特殊变量,可能导致访存错误,但是本次比赛大部分目标函数的实现都是上下文无关的,所以影响不大,偶尔有一些会需要访问 TLS 结构体的可以通过 unicorn 写相关的寄存器完成;
- [扩展] 对每个新的目标函数都要新写一个新的 matcher 和测试用例,希望有办法可以把这个过程自动化,或者说使用一种高度抽象的描述方式,然后运行时转化为 Python 代码;
三、整数溢出检测
3.1 题目要求

3.2 思路
本题难度还是比较大的,要想做好的话需要花不少时间,前期在第一第二题花了不少时间,第三题只能在3天里面极限整了一个仓促的解决方案,最后效果也不尽人意。但是如果继续修改,个人认为还是能产生不错效果。
几个关键的前提:
- 首先是既然要识别整数溢出,那么“溢出”这个动作就肯定由几类运算指令造成,如:SUB, ADD, SHIFT, MUL;
- 单独只看一条指令是无法确认是否存在溢出行为,所以要实现这个方案很可能要用到 符号执行 技术,在符号执行期间,对寄存器或内存位置等变量维护成一个符号值,该值中包含最大可表示整数范围。当符号执行过程中,如果发现存在可能的实际值超过了可表示范围,那就将该指令标记为潜在的溢出指令。其中涉及到一些求解动作还需要 z3 求解器完成;
- 还有一个问题就是 Source 和 Sink,如何知道来自 Source 的输入,会在某指令处发生溢出,最后溢出的值到达 Sink 的哪个参数——这其实是个挺复杂的过程,需要解决的问题很多,其中 污点追踪 就是一个主要难点;
- 为了便于在不同架构的 ELF 上实现符号执行和污点追踪,需要找一个中间语言(IL)来表示,而 Ghidra 反编译器正好会提供一种叫做 P-code 的 microcode,可以抽象的表示不同架构下各种指令的功能;
基于以上几点考虑,我们决定基于科恩实验室开发的一个比较成熟的漏洞检测框架 KeenSecurityLab/BinAbsInspector 开展具体工作
该框架支持使用 Ghidra 的 headless 模式,利于命令行处理数据。并且提供了P-code visitor,可以通过符号执行的方式遍历 P-code,判断指令中某个操作数是否存在潜在的溢出。还提供了各种自带的 Checker,每个 Checker 对应一种 CWE。当程序分析完成后,该框架就可以调用指定 Checker 分析反编译后的程序:
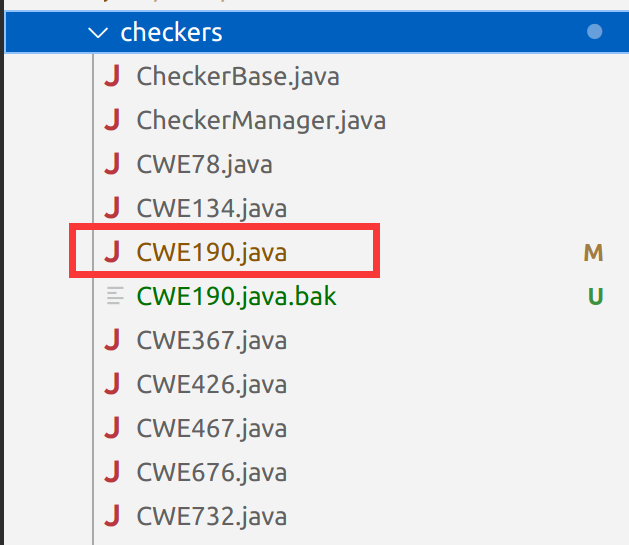
可以发现其中本身就提供了 CWE190 —— 也就是整数溢出的检测模块,但是非常遗憾的是这个模块实现得较为简单,没有针对漏洞特点进行进一步处理,所以漏报率和误报率都很高。
这是原生的代码实现:
/**
* CWE-190: Integer Overflow or Wraparound
*/
public class CWE190 extends CheckerBase {
private static final Set<String> interestingSymbols = Set.of("malloc", "xmalloc", "calloc", "realloc");
public CWE190() {
super("CWE190", "0.1");
description = "Integer Overflow or Wraparound: The software performs a calculation that "
+ "can produce an integer overflow or wraparound, when the logic assumes that the resulting value "
+ "will always be larger than the original value. This can introduce other weaknesses "
+ "when the calculation is used for resource management or execution control.";
}
private boolean checkCodeBlock(CodeBlock codeBlock, Reference ref) {
boolean foundWrapAround = false;
for (Address address : codeBlock.getAddresses(true)) {
Instruction instruction = GlobalState.flatAPI.getInstructionAt(address);
if (instruction == null) {
continue;
}
for (PcodeOp pCode : instruction.getPcode(true)) {
if (pCode.getOpcode() == PcodeOp.INT_LEFT || pCode.getOpcode() == PcodeOp.INT_MULT) {
foundWrapAround = true;
}
if (pCode.getOpcode() == PcodeOp.CALL && foundWrapAround && pCode.getInput(0).getAddress()
.equals(ref.getToAddress())) {
CWEReport report = getNewReport(
"(Integer Overflow or Wraparound) Potential overflow "
+ "due to multiplication before call to malloc").setAddress(
Utils.getAddress(pCode));
Logging.report(report);
return true;
}
}
}
return false;
}
@Override
public boolean check() {
boolean hasWarning = false;
try {
BasicBlockModel basicBlockModel = new BasicBlockModel(GlobalState.currentProgram);
for (Reference reference : Utils.getReferences(new ArrayList<>(interestingSymbols))) {
Logging.debug(reference.getFromAddress() + "->" + reference.getToAddress());
for (CodeBlock codeBlock : basicBlockModel.getCodeBlocksContaining(reference.getFromAddress(),
TaskMonitor.DUMMY)) {
hasWarning |= checkCodeBlock(codeBlock, reference);
}
}
} catch (Exception exception) {
exception.printStackTrace();
}
return hasWarning;
}
}
可以发现这个模块就是直接遍历 Reference 所在 BasicBlock 的指令流,判断是否有潜在的整数溢出运算指令,在此基础上检查是否遇到了调用 Sink 函数的 Call 指令,条件满足则输出。这样会导致肉眼可见的误报。
最终,基于 BinAbsInspector 框架,我们构思了以下的实现思路来实现整数溢出漏洞检测:
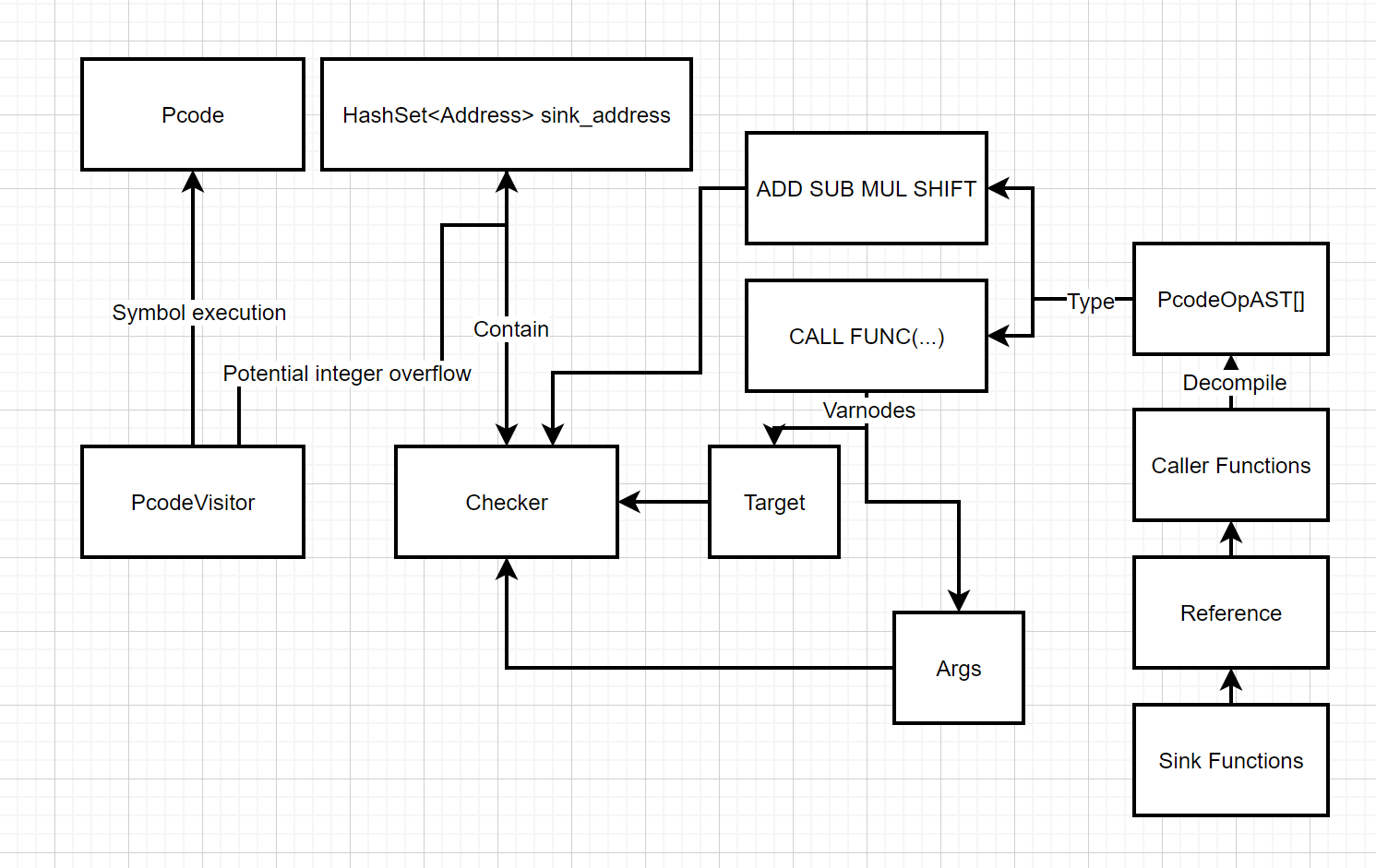
核心就是 PcodeVisitor 和 Checker 上的改动:
- PcodeVisitor 负责完成潜在整数溢出指令的标记
- Checker 负责检查 Sink 处的函数调用参数,以确认其是否受到了被标记指令的影响
- 这里暂时没有实现 Source 的约束,即使框架本身已经提供了 TaintMap 去回溯指令的 Source 函数,主要考虑是避免不小心整出更多 BUG 导致跑不出有分数的答案交上去...
3.3 实现
不太擅长写 Java,写得蠢的地方不要见怪
3.3.1 修改 CWE190 Checker
3.3.1.1 查找到足够的 Sink
在 Checker 模块添加自定义 Sink,并实现扫描程序 Symbol Table 自动提取 Sink 的功能(就是一暴力枚举):
SymbolTable symbolTable = GlobalState.currentProgram.getSymbolTable();
SymbolIterator si = symbolTable.getSymbolIterator();
...
while (si.hasNext()) {
Symbol s = si.next();
if ((s.getSymbolType() == SymbolType.FUNCTION) && (!s.isExternal()) && (!isSymbolThunk(s))) {
for(Reference reference: s.getReferences()){
Logging.debug(s.getName() + ":" + reference.getFromAddress() + "->" + reference.getToAddress());
hasWarning |= checkCodeBlock(reference, s.getName());
}
}
}
...这里首先从符号表提取出所有符号,然后过滤出函数符号,过滤掉 External 符号,过滤掉 Thunk 符号剩下来的作为 Sink。其实这样的过滤还是太粗略的,可以大致总结一些基本不可能成为 Sink 但是又高频使用的常见函数构成黑名单,提取 Sink 时从中过滤一下实测效果会好很多。
3.3.1.2 使用 High-Pcode
不再直接遍历 CodeBlock 中的 Instruction,因为这样使用的是 Raw-Pcode。与 Raw-Pcode 相对应的是 High-Pcode。Raw-Pcode 只是将返汇编指令直接抽象出来得到中间的表示方式,它的 CALL 指令无法表示函数调用的参数信息。而 High-Pcode 是经过 AST 分析后得到的,其包含的 Varnode 具有语法树上的关联关系,CALL 指令也包含了传入的参数
先获取 Sink 函数的引用点所在函数,调用 decompileFunction 进行反编译,分析函数的AST结构,并得到 High Function,由 High Function 可以获得 PcodeOpAST,PcodeOpAST 继承自 PocdeOp 类,也就是上面所说的 High-Pcode
DecompileOptions options = new DecompileOptions();
DecompInterface ifc = new DecompInterface();
ifc.setOptions(options);
// caller function
Function func = GlobalState.flatAPI.getFunctionContaining(ref.getFromAddress());
if (func == null) {
Logging.debug("Function is null!!!");
return false;
}
if (!ifc.openProgram(GlobalState.currentProgram)) {
Logging.debug("Decompiler" + "Unable to initialize: " + ifc.getLastMessage());
return false;
}
ifc.setSimplificationStyle("decompile");
Logging.debug("Try to decompile function...");
DecompileResults res = ifc.decompileFunction(func, 3000, null);
if (res == null) {
Logging.debug("Decompile res is null!!!");
return false;
}
Logging.debug("Decompile success!");
HighFunction highFunction = res.getHighFunction();
if (highFunction == null) {
Logging.debug("highFunction is null!!!");
return false;
}
Iterator<PcodeOpAST> pCodeOps = highFunction.getPcodeOps();
if (pCodeOps == null) {
Logging.debug("pCodeOps is null!!!");
return false;
}3.3.1.3 污点指令识别
迭代遍历函数中所有的 pCode,判断是否属于4种算数运算之一,如果是的话则检查 PcodeVisitor 是否有将该指令标记为潜在溢出指令。如果条件都符合则标记 foundWrapAround 为真,并保存最后一条潜在溢出指令地址到 lastSinkAddress
while(pCodeOps.hasNext()) {
if(found){
break;
}
pCode = pCodeOps.next();
if (pCode.getOpcode() == PcodeOp.INT_LEFT
|| pCode.getOpcode() == PcodeOp.INT_MULT
|| pCode.getOpcode() == PcodeOp.INT_ADD
|| pCode.getOpcode() == PcodeOp.INT_SUB) {
if(PcodeVisitor.sink_address.contains(Utils.getAddress(pCode))){
foundWrapAround = true;
// get pCode's address and store it in lastSinkAddress
lastSinkAddress = Utils.getAddress(pCode);
} else{
Logging.debug("sink_address set does not contain: "+String.valueOf(Utils.getAddress(pCode).getOffset()));
}
}
...
}其中 PcodeVisitor.sink_address 是下文添加的一个用于保存潜在溢出指令的数据结构3.3.1.4 CALL 指令参数检查
因为不能直接认为潜在整数溢出指令就一定会导致后续 CALL 所调用的 Sink 函数会受到整数溢出影响,所以还需要明确整数溢出的位置是否影响到了函数的参数。为了提高效率,可以只检查函数的 size 参数或者 length 参数的位置,将这些位置对应的 Varnode 的 def 地址和 lastSinkAddress 作比较来确定参数是否受到溢出影响(事实上这操作也有一些问题)。
switch(symbolName){
...
case "calloc":
if(pCode.getInput(1) == null && pCode.getInput(2) == null){
Logging.debug("Input(1) & Input(2) is null!");
break;
}
found = true;
if (Utils.getAddress(pCode.getInput(1).getDef()) == lastSinkAddress
|| Utils.getAddress(pCode.getInput(2).getDef()) == lastSinkAddress) {
found = true;
}
break;
case "realloc":
if(pCode.getInput(2) == null){
Logging.debug("Input(2) is null!");
break;
}
found = true;
if (Utils.getAddress(pCode.getInput(2).getDef()) == lastSinkAddress) {
found = true;
}
break;
...
}3.3.2 修改 PcodeVisitor
这个模块主要完成符号执行的功能,如果某条指令发生了潜在的整数溢出可以通过 Kset 的 isTop() 方法来检查3.3.2.1 标记潜在整数溢出指令
添加一个 public 的静态 HashSet 变量,用于保存那些被符号执行认为存在潜在整数溢出的指令
public static HashSet<Address> sink_address = new HashSet<Address>();3.3.2.2 检查四种运算指令的整数溢出
在 PcodeVisitor 对之前提到的四种运算指令进行符号执行时,通过 isTop() 检查 Pcode 的两个 Input Varnode 和一个 Output Varnode 对应的符号值是否存在潜在的整数溢出,如果有则标记到 HashSet<Address> sink_address 中以便 Checker 访问
public void visit_INT_MULT(PcodeOp pcode, AbsEnv inOutEnv, AbsEnv tmpEnv) {
Varnode op1 = pcode.getInput(0);
Varnode op2 = pcode.getInput(1);
Varnode dst = pcode.getOutput();
KSet op1KSet = getKSet(op1, inOutEnv, tmpEnv, pcode);
KSet op2KSet = getKSet(op2, inOutEnv, tmpEnv, pcode);
KSet resKSet = op1KSet.mult(op2KSet);
setKSet(dst, resKSet, inOutEnv, tmpEnv, true);
updateLocalSize(dst, resKSet);
// CWE190: Integer Overflow
if (resKSet.isTop() || op1KSet.isTop() || op2KSet.isTop()) {
Logging.debug("Add new sink address: "+String.valueOf(Utils.getAddress(pcode).getOffset()));
sink_address.add(Utils.getAddress(pcode));
}
IntegerOverflowUnderflow.checkTaint(op1KSet, op2KSet, pcode, true);
}3.3.3 运行效果

3.4 不足与改进
- [漏报] 不明原因导致的大量漏报,目前该BUG暂未解决,发现问题主要出在 CWE190 Checker 在判断运算指令是否被标记为潜在溢出指令时存在漏判的情况
- [漏报] 一个设计失误,由于时间比较仓促,在实现 Checker 的时候只把函数参数的 def 地址和
lastSinkAddress做了比较,导致如果在 CALL 之前出现多个潜在溢出指令时,可能会无法匹配到正确的那条指令,这也会导致大量的漏报情况 - [资源占用] 资源占用特别大,由于该方案存在大量符号执行和约束求解,使用个人笔记本电脑实验时发生了多次卡死,测试进度缓慢